在上一讲中,我们实战了一把 dagster,了解了各类技术概念,这一次我们来了解一下 dagster 的黄金搭档 DBT,来看下如何组织一个很规范的数据仓库项目。
更新历史
- 2023.07.04: 完成初稿
- 2023.07.05: 更新源代码仓库
写在前面
前面的文章中,我们基本都在 dagster 的体系中操作,作为黄金搭档的 dbt,实际上和 dagster 的 asset 的概念体系并不是完全一致的,我们这一讲的关键,就是理解dbt模型和Dagster软件定义资产(或SDAs)如何协同工作。
dbt models 和 dagster software-defined assets
不熟悉 dbt 的小伙伴可能会有些疑问,为什么这俩框架的核心抽象是类似的?因为随着编程范式的升级,解耦已经从类的层级,再次细分到了类里面的内容如何去抽象地定义,那么就会有:
- 唯一的标识符用于区分:dagster 中的 asset key = dbt model 的名称
- 类似函数的传参表示输入的要求:dagster 的 upstream assset key = dbt model 中的 ref / source
- 对数据处理的具体逻辑:dagster 的 python 代码 = dbt model 中的 SQL 语句
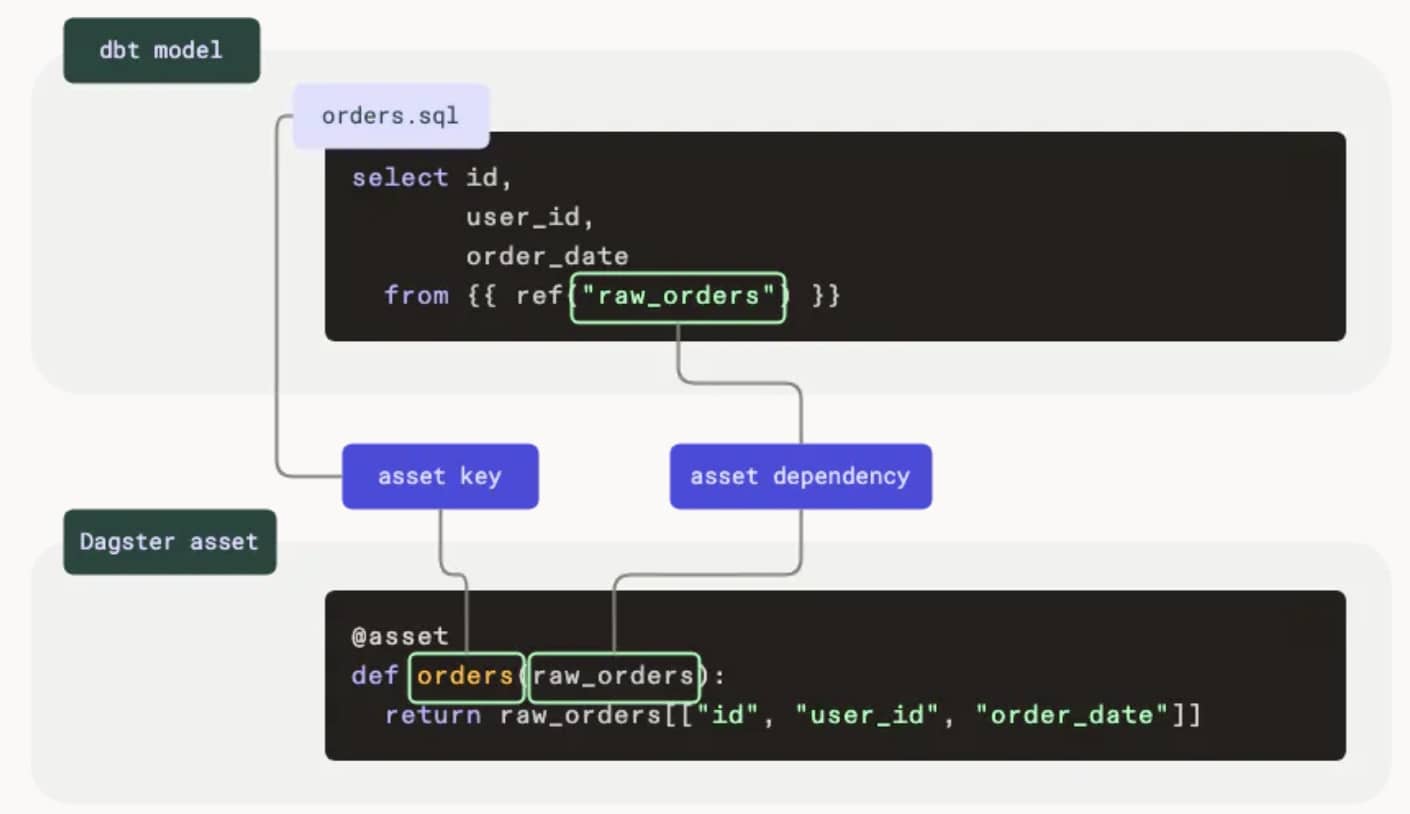
有了这三个点,可以想象一下,其实这俩都是标准的函数定义逻辑,因此很相似就不奇怪了。下面这个图可以更清晰的解释对应关系(来源于官方教程)
环境配置
如果之前已经安装过 dagster,相对来说就比较简单,但这里我们假设啥都没装(但其实也只要一句命令)
1 | 环境安装 |
dbt 配置
dbt 的配置和 dagster 的配置不在一个地方,我们打开 /tutorial_template/jaffle_shop/config/profiles.yml,将下面的内容添加进去,表示这个项目中的 dbt 使用本地的 duckdb 数据库:
1 | jaffle_shop: |
配置完数据库之后,我们需要配置数据源。当然了,现在我们没有任何数据,之后会创建 Dagster 的 Asset 来为 dbt models 提供数据。在 dbt 中,数据源在 /tutorial_template/jaffle_shop/models/sources.yml 中声明,我们将下面的内容填写进去,这里包含 orders_raw 和 customers_raw 两张表,也会对应 dagster 的两个 asset:
1 | version: 2 |
接下来我们需要从表中载入数据了,在 dbt 中,几乎一切都是用 sql 来执行的,所以我们修改 /tutorial_template/jaffle_shop/models/staging 文件夹下的 stg_customers.sql 和 stg_orders.sql,先把数据从 source 中读取出来,内容如下(分别替换,不用管原来里面的内容):
1 | # /tutorial_template/jaffle_shop/models/staging/stg_customers.sql |
到现在为止,项目都还没有能够运行,但不要慌,先让子弹飞一下!
dbt 与 dagster 结合
加载 dbt 模型
为啥说 dbt 和 dagster 他俩是黄金搭档呢,因为前面说到的各种对接都不需要我们自己去映射,直接几行就可以搞定,我们打开 /tutorial_template/tutorial_dbt_dagster/assets/__init__.py,填入如下代码,就可以把 dbt 和 dagster 的连接在一起了:
1 | from dagster_dbt import load_assets_from_dbt_project |
所有的操作都被放到了 load_assets_from_dbt_project 这个方法中,将每个 dbt model 都加载为 dagster 的 asset,具体做三件事:
- 编译 dbt 项目
- 解析 dbt 项目中的 metadata
- 生成一一对应的 asset,对应要执行的操作都是调用 dbt 来生成 model
注:对于小的 dbt 项目,用 load_assets_from_dbt_project 就已经足够了,对于更加大型的项目,就推荐使用 load_assets_from_dbt_manifest 方法从 dbt 的 manifest.json 中载入。
定义 Dagster 的代码位置
为什么需要去定义代码位置呢,因为在 dagster 的概念中,有一个叫 Definitions 的类型,用来统一管理 Dagster 的各种 asset 和 resource 能内容。因为我们需要调用 dbt,所以就要把 dbt 注册成为一个 resource 进行统一管理,名为 DbtCliClientResource,都已经封装好了,直接用就行。在 /tutorial_template/tutorial_dbt_dagster/__init__.py 文件中写入如下内容:
1 | import os |
验收一下结果
前面都准备好了之后,我们就可以启动 Dagit(就是 dagster 的 Web UI 界面)来看看效果了,进入 tutorial_template 文件夹,依然是 dagster dev 命令,在 Assets 页面我们就可以看到引入的 dbt 模型了,因为是默认支持的,甚至还有图标噢:
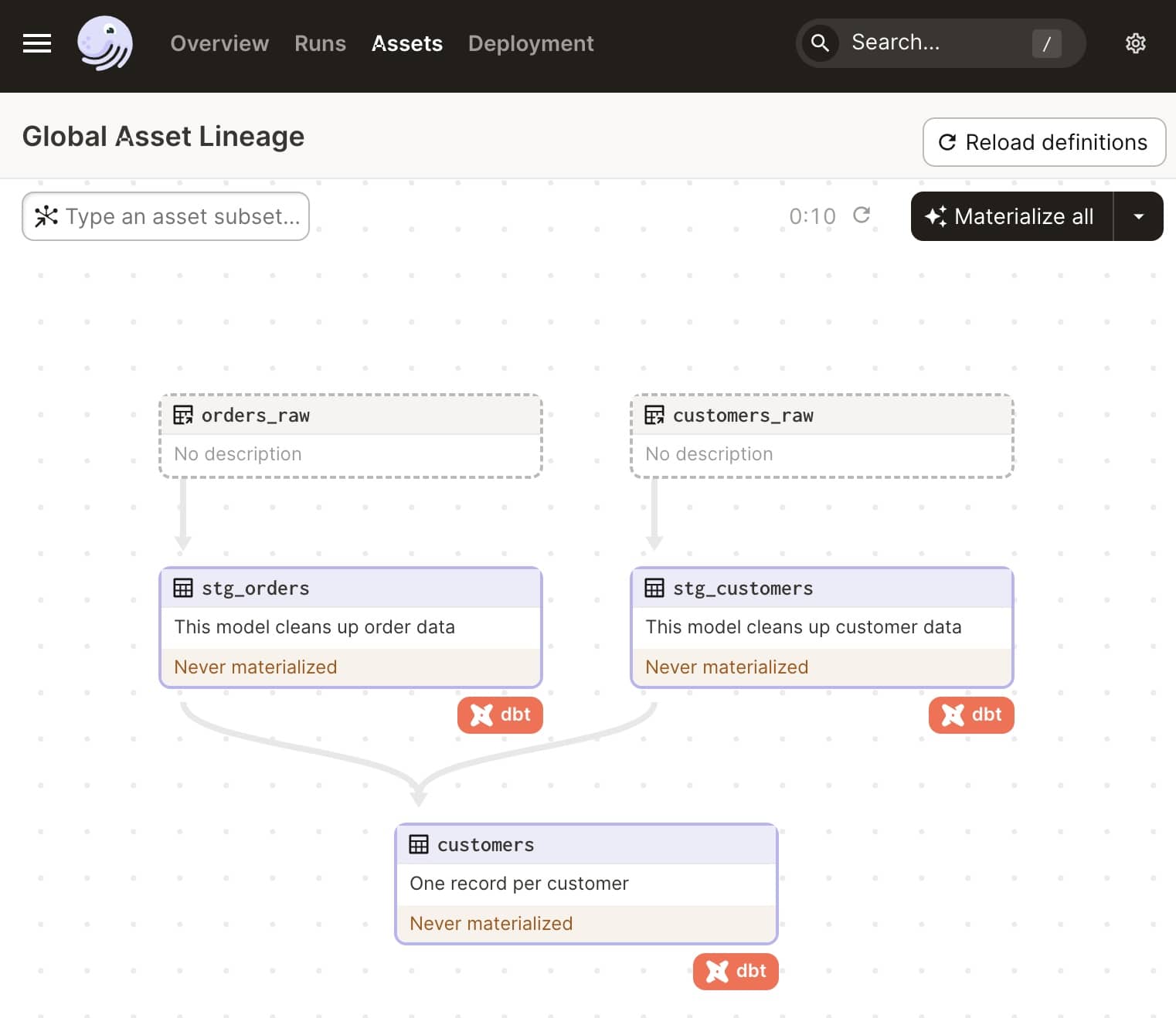
万事俱备只欠东风,接下来我们就可以让项目运行起来了。
添加上游资产
目前我们的 dbt 空有模型没有数据,所以我们要搞 2 个 dagster 的 asset 来供数,在 /tutorial_template/tutorial_dbt_dagster/assets/__init__.py 添加如下内容:
1 | # 在最顶上添加 |
为什么要叫 orders_raw 和 customers_raw 呢?因为我们在 /tutorial_template/jaffle_shop/models/sources.yml 中已经给了 source 的定义,名字如果不匹配就对不上了。这里附上文件内容,大家就不用上去找了:
1 | version: 2 |
我们还可以留意到 group_name 设置为 staging,这样就可以确保和从 dbt 引入的 model 的组保持一致,在下图中我们可以看到 dbt 的有 staging 作为组,而 orders_raw 没有组,所以我们给补上:

设置 I/O Manager
当我们想要物化(Materialize)的时候,就需要告诉 dagster 如何处理输入和输出,我们这里使用 duncdb_io_manager 来负责这个事情,当我们执行具体物化操作的时候,会发生如下事情:
- 将上游资产(customers_raw、orders_raw)的数据加载到 DuckDB 中。这里
duckdb_io_manager使用DuckDBPandasTypeHandler将我们的资产中使用的 pandas DataFrames 存储为 CSV,并将它们加载到 DuckDB 中。 - 将下游资产用于从 DuckDB 中读取数据(下一小节的内容)
我们要更新一下 /tutorial_template/tutorial_dbt_dagster/__init__.py 的代码,用下面的内容替换:
1 | import os |
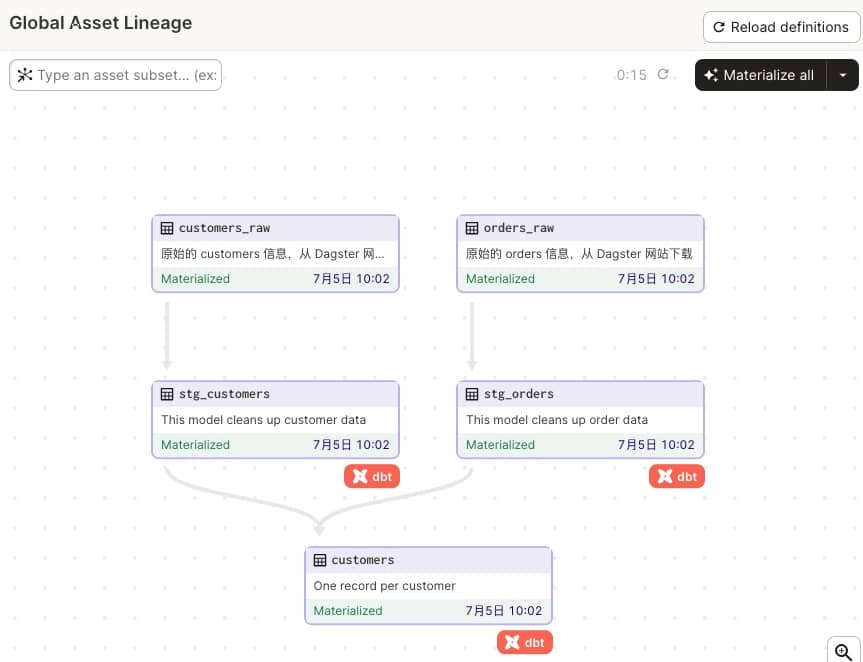
因为修改了代码,所以我们点击一下右上角的 Reload definitions 按钮,发现更新之后,再次点击 Materialize all,就可以正常执行了,完成之后就会有更多执行的信息,如下图所示
添加下游资产
现在我们有了原始数据,又用 dbt 完成了建模,最后就需要去给出一些结果了,同时也可以了解如何引用 dbt 中的 customer asset。
我们继续修改 /tutorial_template/tutorial_dbt_dagster/assets/__init__.py 文件,内容如下:
1 | # 新增引入 |
更新完成之后,我们再次点击 Reload definitions 按钮,可以看到 order_count_chart 现在是在最下面的 asset,如下图所示:

我们可以看到就最下面的显示 Never materialized,我们选择之后点击 Materialize selected,就可以在不重复运行前面 asset 的情况下,物化最新加上的资产。如果一切正常,会自动弹出图表。
至此,我们就学会了如何将 dbt 和 dagster 结合在一起使用,新的旅程就要开始了!