07:28:20 Running with dbt=1.3.1 dbt version: 1.3.1 python version: 3.7.9 python path: /Users/wangda/Dev/venvs/ds37/bin/python os info: Darwin-19.6.0-x86_64-i386-64bit Using profiles.yml file at /Users/wangda/.dbt/profiles.yml Using dbt_project.yml file at /Users/wangda/Documents/Gitee/dbt_hello_world/dbt_project.yml
Configuration: profiles.yml file [OK found and valid] dbt_project.yml file [OK found and valid]
4: 大雨大雪冰雹 Heavy Rain + Ice Pallets + Thunderstorm + Mist, Snow + Fog
temp: 标准化的摄氏度 Normalized temperature in Celsius. The values are derived via (t-t_min)/(t_max-t_min), t_min=-8, t_max=+39 (only in hourly scale)
atemp: 标准化的体感摄氏度 Normalized feeling temperature in Celsius. The values are derived via (t-t_min)/(t_max-t_min), t_min=-16, t_max=+50 (only in hourly scale)
hum: 标准化的湿度 Normalized humidity. The values are divided to 100 (max)
windspeed: 标准化的风速 Normalized wind speed. The values are divided to 67 (max)
casual: 非注册用户数量 count of casual users
registered: 注册用户数量 count of registered users
cnt: 租借单车的数量(全部用户) count of total rental bikes including both casual and registered
看了一眼这些数据,我们可以先利用 group 的能力得到如下一些数据模型:
group by 季节,得到每个季节的趋势
group by 月份,得到每个月份的趋势
group by 天气,得到每种天气的趋势
group by 星期几,得到星期的趋势
这一类的模型建立都很简单,代码如下:
1 2 3 4 5 6 7 8 9 10 11
/* 季节趋势表 */
{{ config(materialized='table') }}
with weather_trend as ( select weathersit, min(temp*47+8) as min_temp, max(temp*47+8) as max_temp, avg(temp*47+8) as mean_temp, sum(casual) as total_casual, sum(registered) as total_registered, sum(cnt) as total_cnt from {{ ref('day') }} groupby weathersit )
13:14:19 Running with dbt=1.3.1 13:14:19 Found 6 models, 4 tests, 0 snapshots, 0 analyses, 289 macros, 0 operations, 2 seed files, 0 sources, 0 exposures, 0 metrics 13:14:19 13:14:19 Concurrency: 1 threads (target='dev') 13:14:19 13:14:19 1 of 6 START sql table model dbt_dev.month_trend ............................... [RUN] 13:14:19 1 of 6 OK created sql table model dbt_dev.month_trend .......................... [SELECT 12 in 0.11s] 13:14:19 2 of 6 START sql table model dbt_dev.my_first_dbt_model ........................ [RUN] 13:14:19 2 of 6 OK created sql table model dbt_dev.my_first_dbt_model ................... [SELECT 2 in 0.05s] 13:14:19 3 of 6 START sql table model dbt_dev.season_trend .............................. [RUN] 13:14:19 3 of 6 OK created sql table model dbt_dev.season_trend ......................... [SELECT 4 in 0.04s] 13:14:19 4 of 6 START sql table model dbt_dev.weather_trend ............................. [RUN] 13:14:20 4 of 6 OK created sql table model dbt_dev.weather_trend ........................ [SELECT 3 in 0.04s] 13:14:20 5 of 6 START sql table model dbt_dev.weekday_trend ............................. [RUN] 13:14:20 5 of 6 OK created sql table model dbt_dev.weekday_trend ........................ [SELECT 7 in 0.05s] 13:14:20 6 of 6 START sql view model dbt_dev.my_second_dbt_model ........................ [RUN] 13:14:20 6 of 6 OK created sql view model dbt_dev.my_second_dbt_model ................... [CREATE VIEW in 0.06s] 13:14:20 13:14:20 Finished running 5 table models, 1 view model in 0 hours 0 minutes and 0.62 seconds (0.62s). 13:14:20 13:14:20 Completed successfully 13:14:20 13:14:20 Done. PASS=6 WARN=0 ERROR=0 SKIP=0 TOTAL=6
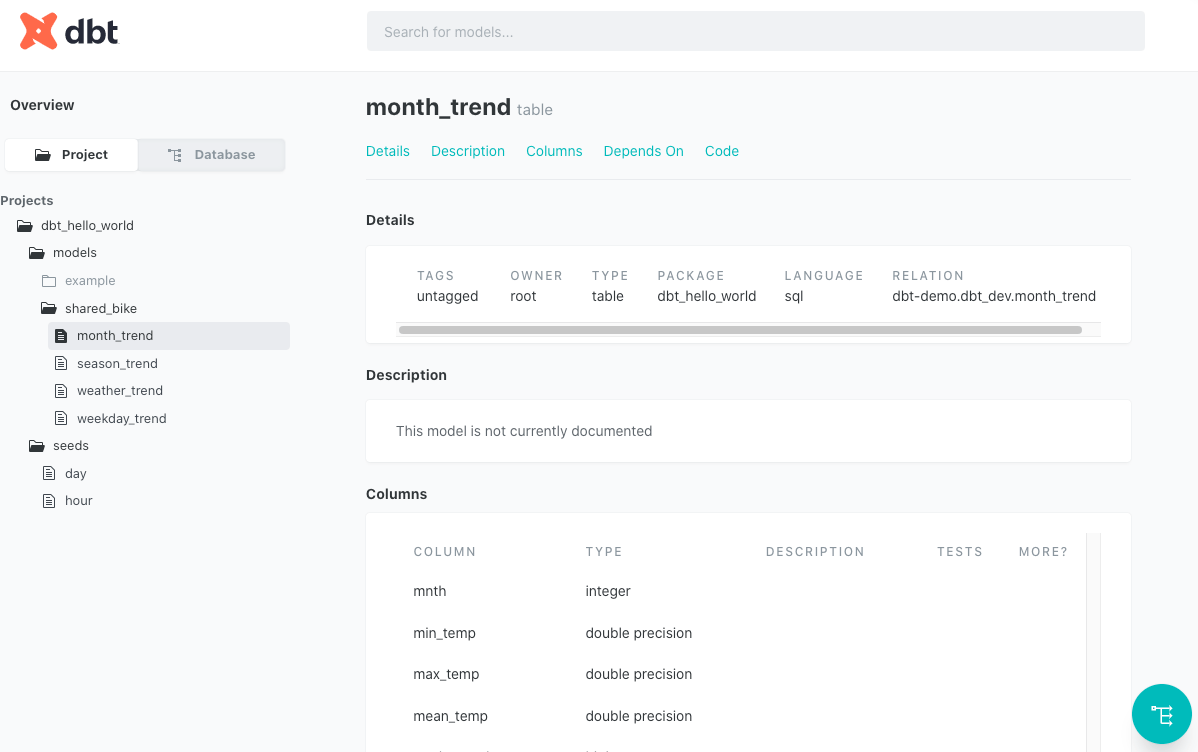
生成文档
dbt 的一大好处就是可以自动根据 sql 语句生成文档,命令如下:
1 2 3 4
# 生成文档 dbt docs generate # 文档本地访问 dbt docs serve
得到结果如下
1 2 3 4 5 6 7 8
13:41:09 Running with dbt=1.3.1 13:41:09 Found 6 models, 4 tests, 0 snapshots, 0 analyses, 289 macros, 0 operations, 2 seed files, 0 sources, 0 exposures, 0 metrics 13:41:09 13:41:10 Concurrency: 1 threads (target='dev') 13:41:10 13:41:10 Done. 13:41:10 Building catalog 13:41:10 Catalog written to /Users/wangda/Documents/Gitee/dbt_hello_world/target/catalog.json