本文主要介绍了斯坦福大学做的一项前瞻性研究,让不同的 AI 角色进行交互,模拟人类。原文标题为,生成代理:人类行为的交互式模拟。
- 注 1:我个人的一些理解补充,主要放在文中的括号内,并会带有
注:
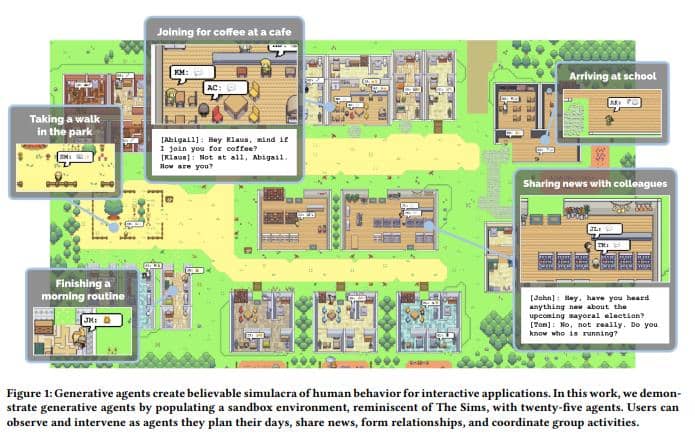
图 1:生成代理人为交互应用程序创建逼真的人类行为模拟。在这项工作中,我们通过将二十五个代理人放置在一个沙盒环境中(类似于The Sims,模拟人生),展示了生成代理人的能力。用户可以观察和干预代理人的日常计划、分享新闻、建立关系以及协调团体活动。
摘要 Abstract
可信的人类行为代理体可以赋能各种交互式应用,包括沉浸式环境、人际交流排练空间、原型工具等。在本文中,我们介绍了生成代理人——计算软件代理,模拟可信的人类行为。生成代理人会起床、做早餐、去上班;艺术家绘画,作家写作;他们形成意见,关心彼此,并发起对话;他们回忆和反思过去的日子,规划着未来。
为实现生成代理人,我们描述了一种架构,扩展了一个大型语言模型,使用自然语言存储代理人完整的经历记录,随着时间的推移将这些记忆综合成更高层次的反思,并动态检索它们来规划行为。我们实例化生成代理人以填充由The Sims启发的交互沙盒环境,使用自然语言与二十五个代理人的小镇进行交互。在评估中,这些生成代理人产生了可信的个体和涌现出了社会行为:例如,从仅有一个用户指定的观念开始,即一个代理人想要举办情人节聚会,代理人自主地在接下来的两天里传播聚会的邀请,结交新朋友,邀请彼此参加聚会,并协调好一起在正确的时间出现聚会。我们通过实验证明,我们代理人架构的组件——观察、规划和反思——每个都对代理人行为的可信度有关键影响。通过将大型语言模型与计算、交互代理人融合,本工作引入了架构和交互模式,以实现可信的人类行为模拟。
CCS CONCEPTS - ACM(Association for Computing Machinery)提供的一种计算机分类法
- 以人为中心的计算 → 交互式系统和工具;
- 计算方法学 → 自然语言处理。
1 介绍 Introduction
我们如何打造一个能反映真实人类行为的交互式人工社会?从沙盒游戏《模拟人生》到认知模型和虚拟环境等应用程序,研究人员和从业者已经设想了计算机代理,可以作为可信的人类行为代理。在这些设想中,计算机驱动的代理会根据他们的过去经验一致地行动,并对环境做出可信的反应。这种对人类行为的模拟可以用现实的社会现象填充虚拟空间和社区,训练人们如何处理罕见但困难的人际关系情况,测试社会科学理论,为理论和可用性测试制作模型人类处理器,为无处不在的计算应用和社交机器人提供支持,能够在一个开放的世界中处理复杂的人际关系。
然而,人类行为的空间是巨大而复杂的。尽管大型语言模型在单个时间点模拟可信的人类行为方面取得了惊人的进展,但确保长期一致性的完全通用代理更适合于这样的架构:随着新的交互、冲突和事件的出现和消失,管理不断增长的记忆,同时处理多个代理之间展开的级联社会动态。成功的方法需要能够在长时间内检索相关事件和互动,反思这些记忆以推广和得出更高层次的推论,并应用这种推理来创建既符合当下情况,又符合代理行为长期发展趋势的计划和反应。
在本文中,我们介绍了基于生成模型的生成代理——代理人可以模拟可信的人类行为,并证明它们能够产生可信的个人和涌现群体行为的仿真。生成代理可以对自己、其他代理和环境进行广泛的推理;他们制定每日计划,反映他们的特点和经验,在适当时行动,做出反应和重新计划;当最终用户更改他们的环境或使用自然语言命令时,他们会做出回应。例如,生成代理会在发现自己的早餐糊了时关闭火炉,在卫生间正在使用时等待外面,并在遇到想要交谈的另一个代理时停下来聊天。一个充满生成代理的社会表现出新的社交动态,形成新的关系、信息扩散和代理之间的协调。
为了实现生成代理人,我们描述了一种代理人架构,利用大型语言模型存储、合成和应用相关的记忆来生成可信的行为。我们的架构包括三个主要组件。第一个是记忆流,是一个长期记忆模块,以自然语言记录代理人经历的全面列表。检索模型将相关性、近期性和重要性相结合,以展现需要的记录,为代理人的及时行为提供信息。第二个是反思,它将记忆综合成随着时间推移逐渐提高的推理,使代理人能够在指导其行为时对自身和他人进行结论。第三个是规划,它将这些结论和当前环境转化为高层次的行动计划,然后递归地转化为详细的行为和反应。这些反思和计划被反馈到记忆流中,影响代理人未来的行为。
注:这一段提出的 记忆流 - 反思 - 规划 架构非常重要,在我们的代码实现中,可以基于这个逻辑进行代理人的思维架构设计
这种架构在多个领域中具有应用,从角色扮演和社交原型到虚拟世界和游戏。在社交角色扮演场景中(例如面试准备),用户可以安全地排练困难的、充满冲突的对话。在原型设计社交平台时,设计师可以超越临时人物,原型动态的、随着时间推移展开的复杂互动。针对本文的目的,我们专注于创造一个受到《模拟人生》等游戏启发的小型交互社会。通过将我们的架构连接到ChatGPT大型语言模型,我们在游戏环境中实现了由25个代理组成的小规模社会。最终用户可以观察和与这些代理互动。例如,如果最终用户或开发人员希望小镇举办一场游戏内情人节聚会,传统游戏环境需要手动编写数十个角色的行为脚本。我们证明,通过使用生成代理人,只需要告诉一个代理人她想要举办聚会就足够了。尽管存在许多潜在的失败点——聚会策划者必须记得通知其他代理人参加聚会,参加者必须记得邀请,那些记得的人必须决定是否真的出现,以及其他可能存在的失败点——我们环境中的代理人成功了。他们成功地宣传了聚会并出席了活动,其中一个代理人甚至邀请了另一个代理人参加聚会,所有这些行为都来源于这一个由用户创建的种子建议。
我们进行了两项生成代理人的评估:一项控制性评估,测试代理人在孤立环境中是否能产生可信的个人行为,另一项端到端的评估,其中生成代理人在两天的游戏时间内以开放式方式相互交互,以了解它们的稳定性和涌现的群体行为。在技术评估中,我们利用一种方法论,通过自然语言“采访”代理人来评估代理人的知识和行为,以探索代理人在角色扮演、记忆、规划、反思等方面的表现。我们比较了几种限制代理的记忆、反思和规划能力的方法。我们观察到,这些组件分别对跨多个采访任务的强效表现至关重要。在技术和端到端的评估中,最常见的错误出现在代理人无法检索相关的记忆、制造虚构记忆的情况,或从语言模型中继承了过于正式的语言和行为方面。
注:实际上这些常见的错误也是大模型本身的存在的问题,即一本正经胡说八道。另外针对非英语的能力测试可能也和英语有一定区别
综上所述,本文的贡献如下:
- 生成代理,可以动态地根据代理人的不断变化的经验和环境生成可信的人类行为仿真。。
- 一种新颖的架构,使生成代理可以通过动态演变的情况记忆、检索、反思、与其他代理交互和规划。这种架构利用大型语言模型的强大提示能力,并补充这些能力以支持更长期的代理一致性,管理动态演变的记忆,并递归地产生更多的演化。
- 两种评估(控制性评估和端到端评估),建立了架构组件重要性的因果效应,并确定了引起问题的原因,例如不适当的记忆检索。
- 讨论生成代理在交互式系统中的机会、伦理和社会风险。我们认为,这些代理应该进行调整,以减轻用户形成假性社交关系的风险,记录日志以减轻深度伪造和量身定制的说服风险,并以补充而不是取代在设计过程中的人类利益相关者的方式应用。
2 相关工作 Related Work
在本节中,我们回顾了人类-人工智能交互的先前文献,并将构建可信人类行为代理的议程置于其规范中。这个规范曾经被交互、游戏和人工智能社区称为北极星,但由于人类行为的复杂性,一直存在挑战。我们综合这项研究,建议使用适当的架构,虽然大型语言模型本身不足以创建可信代理,但开辟了一条新的角度。
2.1 Human-AI Interaction
交互式人工智能系统旨在将人类的洞察力和能力与计算机组件相结合,从而增强其用户的能力。长期以来,人们一直在探索如何允许用户交互式地指定模型的行为。例如,Crayons展示了交互式机器学习的早期愿景,允许非专业用户对分类器进行培训。进一步的工作帮助明确了最终用户如何通过示例和/或演示向系统描述他们的分类目标。最近的工作将这些探索扩展到了深度学习和基于提示的创作。
与此同时,人机交互中的语言和代理交互也一直是研究的一个持续主题。像SHRDLU和ELIZA这样的先驱性工作展示了与计算机系统进行自然语言交互的机会和风险。随着研究的进行,变得清晰的是自主代理人可以提供新的委托和交互隐喻,但人与代理人之间的委托界线仍在不断讨论和精细化。最近,这项技术已经足够稳定,使得代理人可以在大型和复杂的在线社交环境中通过自然语言进行交互。
自然语言交互提供了一种新颖的方式,可以扩展用户在诸如照片编辑和代码编辑等领域的能力。
我们汇集这些工作,以展示我们现在可以为交互式系统创建代理人,用自然语言与他们交互。通过这样做,这项工作重新开启了研究人类认知模型(如GOMS和KLM)、原型设计工具以及普及计算应用等关键人机交互问题的大门。
2.2 Believable Proxies of Human Behavior
以前的文献曾将可信度或可信代理描述为中心设计和工程目标。可信代理旨在提供生命的幻象,并在他们看似自主地做出决策和行动的方式上呈现现实主义的表象,类似于迪士尼电影中的角色。这些代理可以在像我们所居住的那样的开放世界环境中生存和观察,并通过与用户或其他代理进行社交互动来展示出基于社交互动产生的新颖行为,以成为我们在个人和社区虚拟模拟中行为的可信代理。
历史上,这些代理是在智能游戏NPC的背景下开发的。如果可能创建可信的NPC行为,则可以通过启用新颖的叙事和与代理的社交交互,增强玩家在游戏和交互小说中的体验。然而,更重要的是,游戏世界提供了越来越逼真的真实世界描述,如Laird和van Lent在2001年所观察到的,模拟世界为可信代理的开发者提供了可访问的实验场所,以优化代理的认知能力,无需担心在真实世界中实现机器人或从头开始创建模拟环境等问题。
在过去40年中,出现了多种创建可信代理的方法。然而,在实现中,这些方法往往简化代理行为的环境或维度,以使工作更加可管理。像有限状态机和行为树这样的基于规则的方法提供了人工编写代理行为的暴力方法,是当今最主流的方法,并甚至可以处理基础的社交互动,如Mass Effect和The Sims等模拟游戏。然而,手工制作能够全面应对开放世界中可能互动的广度的行为是不可行的,这意味着生成的代理行为可能不能充分地反映其互动的后果,并且无法执行未在脚本中硬编码的新程序。另一方面,用于创建可信代理的普遍学习方法,如强化学习,通过让代理学习其行为,已经克服了手动编写的挑战,并在最近几年的游戏中取得了超凡的表现,如AlphaStar和OpenAI Five(针对 Dota2)。然而,它们的成功主要在于具有明确可定义奖励的对抗性游戏,学习算法可以针对优化,还没有解决在开放世界中创建可信代理的挑战。
计算中的认知架构被纽厄尔引入,旨在建立支持全面认知功能的基础设施,以适应可信代理的全面性质。这些架构推动了可信代理的早期示例。例如,Quakebot-SOAR和ICARUS在第一人称射击游戏中生成了NPC,而TacAir-SOAR在空战训练模拟中生成了飞行员。这些代理使用的架构不同(Quakebot和TacAir-SOAR依赖于SOAR,而ICARUS依赖于其受SOAR和ACT-R启发的变体),但它们共享相同的基本原则。它们维护短期和长期记忆,用符号结构填充这些记忆,并在感知-规划-行动循环中操作,动态感知环境,并将其与手工制作的行动过程匹配。使用认知架构创建的代理旨在适用于大多数,如果不是全部的开放世界情境,并展现出其时代的强健行为。然而,它们的操作空间仅限于手工制作的程序知识,并且它们没有提供一种机制,通过该机制代理可以受到启发,寻求新的行为。因此,这些代理大多部署在非开放世界情境,例如第一人称射击游戏或方块世界中。
注:认知框架很重要,要站在巨人肩膀上。目前的框架不适合开放世界,本质上还是自由度高一点的编程逻辑
如今,按其原始定义创建可信代理仍然是一个有待解决的问题。许多人已经开始讨论,认为尽管现有的创建可信代理的方法可能有些繁琐和有限,但它们足以支持现有的游戏玩法和交互。我们的观点是,大型语言模型提供了一个机会,重新审视这些问题,前提是我们能够构建一个有效的架构,将记忆合成为可信行为。本文提供了朝向这样一种架构的一步。
2.3 Large Language Models and Human Behavior
生成式代理利用大型语言模型为其行为提供动力。关键观察是,大型语言模型在其训练数据中编码了广泛的人类行为。如果在一个狭义的环境下提供提示,这些模型就可以用于生成可信的行为。最近的研究证明了这种方法的有效性。例如,Social Simulacra使用大型语言模型生成用户,这些用户将在新的社交计算系统中出现,以原型制作他们紧迫的社交动态。这种方法使用提示链来生成简短的自然语言描述,描述角色及其在被原型化的系统中的行为。其他经验研究复制了现有的社会科学研究、政治调查和生成合成数据。
注:社会科学研究是一个很可能的方向,完全超越了目前更多依靠人工调查的方式
大型语言模型也被用于生成用户可以与之互动的交互式人类行为。例如,在游戏中,这些模型已被用于创建交互式小说和文本冒险游戏。由于它们能够生成和分解行动序列,因此大型语言模型在规划机器人任务方面也被广泛使用。例如,当机器人被要求完成一个任务,例如拿起一瓶子时,模型会被提示将任务分解成较小的行动序列,如前往桌子找到瓶子并将其拿起。
我们认为,基于上述工作,大型语言模型可以成为创建可信代理的关键组成部分。现有文献在很大程度上依赖于可以视为一阶模板的模板,它们采用了少量提示或思维链提示。这些模板在生成仅基于代理当前环境的行为方面非常有效(例如,一个巨魔如何回应给定的帖子,机器人需要采取哪些行动才能进入一个有门的房间)。然而,可信代理不仅需要基于其当前环境的条件,还需要基于大量的过去经验进行条件,这在(由于基础模型的上下文窗口有限)一阶提示方面效果不佳(当今仍不可能)。最近的研究尝试超越一阶提示,通过增加静态知识库和信息检索方案或简单的总结方案来扩展语言模型。本文将这些想法扩展到构建一个代理架构,该架构处理检索,其中过去的经验在每个时步动态更新,并混合与代理当前上下文和计划,可能会相互强化或矛盾。
注:超越一阶提示,这个是很重要的区别
3 生成式代理的行为和交互 Generative Agent Behavior And Interaction
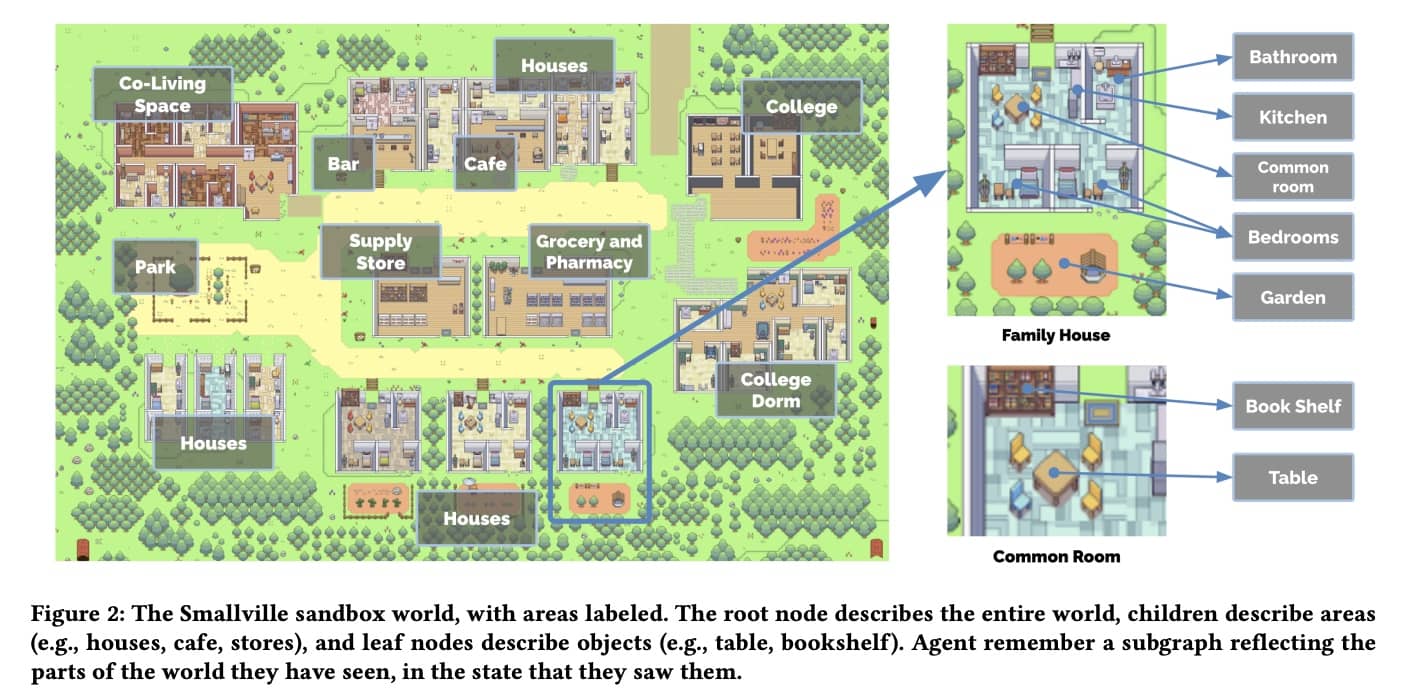
图2: Smallville 沙盒世界,带有标记的区域。根节点描述整个世界,子节点描述区域(例如,房屋、咖啡馆、商店),叶节点描述对象(例如,桌子、书架)。代理会记住一个子图,反映他们所看到的世界的部分状态。
注:这里利用了图和子图的关系,这个实际上可以理解为注意力的上下文
为了具体说明生成式代理的作用,我们将它们作为角色实例化到像《模拟人生》的简单沙盒世界中。这个基于精灵的沙盒游戏世界 Smallville,唤起了一个小镇环境。在本节中,我们将介绍在 Smallville中与生成式代理互动的能力和交互,并描述了代理在其中的行为。然后,在第4节中,我们介绍了支持这些能力和交互的生成式代理架构。在第5节中,我们描述了沙盒环境的实现方式以及代理如何与沙盒世界的底层引擎交互。
3.1 代理的头像和交流形式 Agent Avatar and Communication
Smallville 中居住着25个独特的代理。每个代理都用简单的精灵头像来代表。我们为每个代理撰写了一段自然语言描述,描述了他们的身份特点,包括职业和与其他代理的关系,作为种子记忆。例如,John Lin的描述如下:
John Lin是Willow市场和药店的药房店主,喜欢帮助他人。他一直在寻找让客户获取药物更容易的方法;John Lin和他的妻子Mei Lin以及儿子Eddy Lin住在一起,Mei Lin是一名大学教授,Eddy Lin正在学习音乐理论;John Lin非常爱他的家人;John Lin已经认识旁边的老夫妻Sam Moore和Jennifer Moore几年了;John Lin认为Sam Moore是一个友善、善良的人;John Lin很了解他的邻居Yuriko Yamamoto;John Lin知道他的邻居Tamara Taylor和Carmen Ortiz,但从未见过面;John Lin和Tom Moreno是Willows市场和药店的同事;John Lin和Tom Moreno是朋友,喜欢一起讨论本地政治;John Lin对Moreno家庭也有些了解——丈夫Tom Moreno和妻子Jane Moreno。
每个以分号分隔的短语将作为代理的初始记忆,在模拟开始时输入。
注:在我们的实现中,同样需要为每一类人给出这样以分号分隔的短语,每次生产一个新的代理,实际上就是一个新的对话上下文,加上这段初始记忆。
3.1.1 Inter-Agent Communication
代理之间的交互通过行动和自然语言实现。在每个沙盒引擎的时间步骤中,代理输出一个描述其当前行动的自然语言语句,例如“Isabella Rodriguez正在写她的日记”、“Isabella Rodriguez正在检查邮箱”、“Isabella Rodriguez正在和家人通电话”或“Isabella Rodriguez正在准备睡觉”。这个语句然后被翻译成影响沙盒世界的具体动作。这个行动在沙盒界面上显示为一组表情符号,提供一个俯视图中行动的抽象表示。为了实现这一点,系统采用了一个语言模型,将行动翻译成一组表情符号,这些表情符号出现在每个头像上方的对话气泡中。
注:通过这一段的说明,沙盒引擎的是按照时间分片的,那么具体这个分片是多少,需要进行设计,就是这个虚拟世界中最小的时间单位。
可以通过点击代理头像来查看行动的完整自然语言描述。代理之间以完整的自然语言进行通信。代理知道周围区域中的其他代理,生成式代理架构决定他们是否经过或参与对话。这里是代理Isabella Rodriguez和Tom Moreno在讨论即将到来的选举中间的一段对话样本:
Isabella:我仍在权衡我的选择,但我已经和Sam Moore讨论了选举。你对他有什么想法?
Tom:老实说,我不喜欢Sam Moore。我认为他与社区脱节,没有关注我们的最佳利益。
3.1.2 User Controls
运行此模拟的用户可以操纵模拟并进行干预,可以通过与代理的对话进行交流,也可以通过向代理发出“内部声音”形式的指令进行干预。
用户通过自然语言与代理交流,通过指定代理应该认为他们是什么人物角色来进行交流。例如,如果用户指定自己是一个新闻“记者”,并询问关于即将到来的选举,“谁在竞选职位?”,John代理回复
John:我的朋友Yuriko、Tom和我已经在讨论即将到来的选举并讨论了候选人Sam Moore。我们都同意投票给他,因为我们喜欢他的政纲。
为了直接指挥其中一个代理,用户会扮演代理的“内部声音”的角色,这使代理更有可能将该语句视为指令。例如,当用户作为John的内心声音告诉他“你将要在即将到来的选举中与Sam竞选”,John决定参选,并与他的妻子和儿子分享了他的候选人身份。
注:这个影响逻辑和《十三层空间》的逻辑非常像,一个是通过外人影响,一个是直接干预意识。我们在模拟中也要支持这两种干预方式。
3.2 与环境结合 Environmental Interaction
Smallville拥有一个小型村庄的共通设施,包括咖啡馆、酒吧、公园、学校、宿舍、房屋和商店。它也定义了子区域和物体,让这些空间变得功能性,比如房子里有厨房,厨房里有炉子(图3)。所有被代理人当作主要居住区的地方都有床、书桌、壁橱、架子、浴室和厨房。
代理人在Smallville里的移动方式就像在简单的视频游戏里一样,进出建筑物、浏览地图并向其他代理人靠近。代理人的移动是由生成式代理构建和沙盒游戏引擎控制的:当模型规定代理人要前往某个地方时,我们会在Smallville环境中计算到目的地的步行路径,代理人开始移动。此外,用户还可以作为代理人进入Smallville的沙盒世界运作。用户所化身的代理人可以是已经存在于世界中的代理人,例如Isabella和John,或者是一个没有先前历史的外来访客。Smallville的居民不会对用户控制的代理人有任何不同的待遇。他们会认识到其存在,发起互动,并在形成对它的看法之前记住其行为。
用户和代理可以像沙盒游戏The Sims一样影响这个世界中物体的状态。例如,当代理人睡觉时,床可以被占领;当代理人用完做早餐的材料时,冰箱可以变空。最终用户也可以通过使用自然语言来重新塑造Smallville中代理人的环境,改变代理人周围物体的状态。例如,当Isabella在早上做早餐时,用户可以通过向系统输入一个命令来选择对象并说明其新状态,将厨房炉子的状态由“打开”更改为“燃烧”,像这样:<Isabella的公寓:厨房:炉子>正在燃烧。Isabella会在下一刻注意到这一点,并关闭炉火重新做早餐。同样,如果用户将Isabella浴室的状态设置为“渗水”,当她进入浴室时,她会从她的客厅取工具来修理漏水的地方。
注:这个实际涉及到可视化的展示,当然,前期只是一个内部状态。
3.3 样例的一天 Example “Day in the Life”
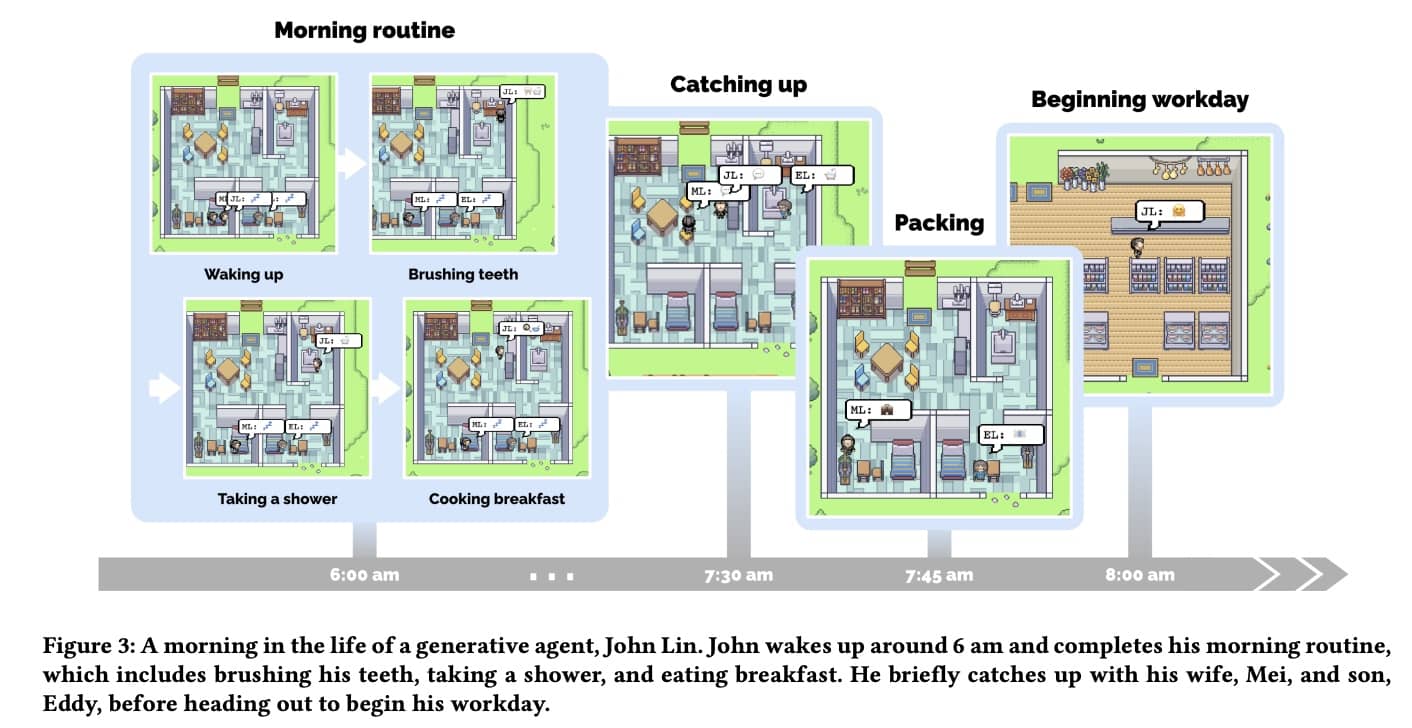
图3:生成式代理人John Lin的一个早晨。约翰早上6点左右醒来,完成早晨例行活动,包括刷牙、淋浴和吃早餐。他在出门开始工作前与妻子Mei和儿子Eddy简短交流了一下。
从单段描述开始,代理人开始规划他们的一天。在沙盒世界中的时间推移,这些代理人的行为会逐渐演变,因为他们相互交互、建立记忆和关系,并协调共同的活动。
我们通过追踪系统在一天中对代理人John Lin的输出来展示生成式代理人的行为表现(见图3)。在林家中,John是第一个在早上7点起床的人。他刷牙、淋浴、穿衣、吃早餐,并在客厅的餐桌上看新闻。在早上8点,Eddy紧随其后,匆忙起床准备上课。当他正准备出门时,他追上了John:
约翰:早上好,艾迪。你睡得好吗?
艾迪:早上好,爸爸。是的,我睡得很好。
约翰:那很好。你今天在忙什么?
艾迪:我正在为我们班写一首新的音乐作品。这周就要交了,所以我正在努力完成。但我玩得很开心!
约翰:听起来不错!
艾迪出发后不久,Mei 醒了过来,和约翰在一起。Mei 问起她的儿子,约翰回忆起他们刚刚的对话:
Mei:艾迪已经去学校了吗?
约翰:是的,他刚走。他正在为他的班级写一首乐曲。
Mei:哦,那太好了!跟我说说。
约翰:我觉得他真的很享受!他说他玩得很开心。
Mei:太好了!我为他感到骄傲。
当他们结束交谈后,Mei和John开始收拾。Mei继续教学并开始撰写她的研究论文,而John在早上9点前在Willow Market and Pharmacy开启他的药房。
3.4 涌现出的社会行为 Emergent Social Behaviors
通过相互交互,Smallville中的生成式代理人交换信息、建立新关系并协调共同活动。扩展之前的工作,这些社交行为是自发出现而不是预先编程的。
注:这里就是涌现出来的社会行为。
3.4.1 信息扩散 Information Diffusion
当代理人注意到彼此时,他们可能会开始对话。在这个过程中,信息可以从一个代理人传递到另一个代理人。
例如,在杂货店,Sam和Tom之间的对话中,Sam告诉Tom他参加了当地的选举:
山姆:嘿,汤姆,最近怎么样?
汤姆:很好,谢谢。有什么事吗?
山姆:嗯,我想和你谈谈。事实上,我要在即将到来的地方选举中竞选市长。
汤姆:真的吗?真是个好消息!你为什么要跑?
山姆:我已经参与当地政治很多年了,我真的觉得我可以为我们的社区带来改变。另外,我想为大家带来新的想法和观点。
那天晚些时候,山姆离开后,汤姆和约翰从另一个消息来源听到了这个消息,他们讨论山姆赢得选举的可能性:
约翰:我听说山姆·摩尔要参加地方选举竞选市长。你认为他有很大的机会获胜吗?
汤姆:我确实认为他有很好的机会。他一直在社区里努力工作,我想他会得到很多支持。你怎么看?
约翰:我认为他参加竞选是件好事。我很好奇还有谁在竞选,选举结果会如何。
渐渐地,山姆的候选人资格成为了镇上的话题,一些人支持他,而另一些人仍未决定
3.4.2 关系记忆 Relationship Memory
Smallville中的代理人随着时间的推移建立新的关系,并记住他们与其他代理人的互动。
例如,Sam在一开始不认识Latoya Williams。他在约翰逊公园散步时遇到了Latoya,并相互介绍。Latoya提到她正在进行一项摄影项目:“我在这里拍照,为我正在进行的一个项目做准备。”在后来的互动中,Sam和Latoya的互动表明了他对那次互动的记忆,因为他问道:“嗨,Latoya。你的项目进展如何?”她回答:“嗨,Sam。进展顺利!”
3.4.3 协作 Coordination
生成式代理人相互协作。
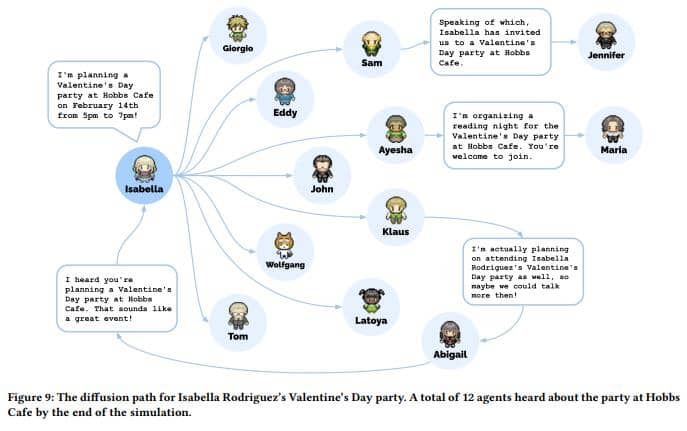
在霍布斯咖啡馆,Isabella Rodriguez被初始化为组织情人节派对,时间是2月14日下午5点到7点。从这个种子开始,代理人在看到朋友和客人时就邀请他们参加派对。接着,Isabella在13日下午开始为派对装饰咖啡馆。Maria是Isabella的常客和密友,她到了咖啡馆,Isabella请求Maria帮忙布置派对,Maria同意了。Maria的人物描述中提到她暗恋Klaus。当晚,Maria邀请她的暗恋对象Klaus参加派对,他愉快地接受了。

图4:在模拟开始时,一个代理人被初始化为组织情人节派对的意图。尽管在随后的事件链中存在许多可能的失误点——代理人可能不会根据那个意图行动,可能会忘记告诉其他人,也可能会忘记出席——但情人节派对还是成功地举行了,有许多代理人参加并互动
情人节那天,包括Klaus和Maria在内的五个代理人在下午5点来到霍布斯咖啡馆,他们共同享受派对的狂欢(见图4)。在这种情况下,终端用户仅设置了Isabella举办派对和Maria暗恋Klaus的最初意图,但派对的传播、布置、邀请、到场以及在派对上的互动等社交行为都是由代理人架构发起的。
4 生成式代理的架构 Generative Agent Architecture

图5:我们的生成式代理人架构。代理人感知他们的环境,所有的感知都被保存在一个包含代理人经验的全面记录中,称为记忆流。基于代理人的感知,该架构检索相关的记忆,然后利用这些检索到的行为来确定一个动作。这些检索到的记忆还用于制定长期计划,并创建更高级别的反思,两者都被输入到记忆流中以备将来使用。
注:上图的架构非常重要,也会直接影响到代理人对现实的理解,需要进行建模和代码化实现。
生成式代理人旨在为开放的世界提供一个行为框架:一个能够与其他代理人进行交互并能够对环境变化做出反应的框架。生成式代理人将它们当前的环境和过去的经验作为输入并产生行为作为输出。支撑这种行为的是一种新型代理人架构,它将大型语言模型与合成和检索相关信息的机制相结合,以使语言模型的输出具有条件性。如果没有这些机制,大型语言模型可以输出行为,但是结果可能不会基于代理人以往的经验做出反应、不会做出重要推理,也可能不会保持长期连贯性。即使是如GPT-4这样最表现良好的模型,长期规划和连贯性也存在挑战。由于生成式代理人产生大量需被保存的事件和记忆流,因此我们架构的主要挑战是确保代理人的记忆中最相关的部分在需要时被检索和综合。
注:关键就是检索+综合+大模型。
我们架构的核心是记忆流,这是一个数据库,记录代理人的全部经历。从记忆流中检索记录,规划代理人的行动并对环境做出适当的反应,将记录递归地合成为更高级别的观察结果,指导行为。架构中的所有内容都以自然语言描述记录和推理,从而使架构能够利用大型语言模型。
我们目前的实现使用了ChatGPT的gpt3.5-turbo版本。我们预计,生成式代理人的架构基础——记忆、规划和反思——将随着语言模型的改进而继续保持不变。更新的语言模型(例如GPT-4)将继续扩展支撑生成式代理人的提示的表达能力和性能。然而,截至目前,GPT-4的API仍然只向受邀用户开放,因此我们的代理人使用的是ChatGPT。
4.1 记忆和回忆 Memory and Retrieval
挑战:创建能够模拟人类行为的生成式代理人需要对一个经验集合进行推理,这个集合比提示中描述的要大得多,因为完整的记忆流可能会分散模型的注意力,而且目前甚至无法适应有限的上下文窗口。考虑Isabella代理人回答“最近你热衷于什么?”这个问题。将所有的Isabella经验总结到语言模型有限的上下文窗口中,将得到一个无信息量的回答,Isabella会讨论一些关于活动与项目的合作、咖啡馆的清洁和组织等话题。而不是总结,下面描述的记忆流会呈现相关的记忆,从而产生更加信息丰富和具体的回答,提到Isabella热衷于让人们感到受欢迎和包容,策划活动并营造人们享受的氛围,比如情人节派对。
方法:记忆流维护代理人经验的全面记录。它是一个存储记忆对象的列表,每个对象包含一个自然语言描述、一个创建时间戳和一个最近访问时间戳。记忆流的基本元素是一个观察,它是一个直接被代理人感知到的事件。常见的观察包括代理人自己执行的行为,或者代理人感知到其他代理人或非代理人对象执行的行为。例如,Isabella Rodriguez在咖啡馆工作,随着时间的推移,可能会积累以下观察:(1) Isabella Rodriguez正在摆放糕点,(2) Maria Lopez正在喝咖啡复习化学考试,(3) Isabella Rodriguez和Maria Lopez正在谈论在霍布斯咖啡馆策划情人节派对,(4) 冰箱是空的。
注:这里的重点是记忆流式如何组成的,实际上就是下图的结构,在实现上我们需要按照这种方式进行。

图6:记忆流包括许多与代理人当前情境相关和不相关的观察。检索确定了一部分这些观察,应该被传递给语言模型,以使它的回应对情境产生条件性。
我们的架构实现了一个检索函数,将代理人的当前情境作为输入并返回一个子集的记忆流,以传递给语言模型。检索功能有许多可能的实现,这取决于代理人在决定如何行动时需要考虑的重要因素。在我们的情境中,我们关注三个主要组件,它们共同产生了有效的结果。
最近性将最近访问的记忆对象分配较高的分数,因此一段时间之前或今天早上的事件可能会留在代理人的注意力范围内。在我们的实现中,我们将最近性视为一个指数衰减函数,它是自上次检索记忆以来游戏时长的指数函数,我们的衰减因子为 0.99。
重要性将普通记忆与核心记忆区分开来,通过对代理人认为重要的那些记忆对象分配较高的分数。例如,像在自己的房间里吃早餐这样的普通事件会得到较低的重要性分数,而与配偶分手这样的事件则会得到较高的分数。重要性分数的实现也有许多可能的方法;我们发现直接向语言模型输出整数分数是有效的。完整的提示如下:
在1到10的范围内,其中1是纯粹的日常事件(例如刷牙、整理床铺),10是极其深刻的事件(例如分手、被大学录取),请为下面的记忆片段评分,表示其可能的深刻程度
记忆: 在The Willows Market and Pharmacy购买杂货
评分: <填写>
此提示为“打扫房间”返回整数值2,为“向你的暗恋表白”返回整数值8。重要性分数是在创建记忆对象时生成的。
注:这里的关键就是每个事件都会根据该代理的特点,生成初始的分数。
相关性为与当前情境相关的记忆对象分配较高的分数。什么是相关的取决于回答“相关于什么?”,因此我们会根据一个查询记忆对相关性进行限制。例如,如果查询是一个学生正在与同学讨论如何复习化学考试,他们的早餐记忆对象应该具有较低的相关性,而关于教师和功课的记忆对象应该具有较高的相关性。在我们的实现中,我们使用语言模型生成文本描述的每个记忆的嵌入向量。然后,我们将相关性计算为该记忆的嵌入向量与查询记忆的嵌入向量之间的余弦相似性。
注:经典的利用 embedding 进行相似性比较,有很多现成的库可以进行,但是注意,需要是每一行是一个词嵌入。
为了计算最终权重得分,我们通过最大值最小值缩放将最近性、相关性和重要性分数归一化到[0,1]范围内。检索函数将所有记忆作为三个元素的加权组合进行评分:

在我们的实现中,所有的 𝛼 都设置为1。排名靠前的记忆将被包含在语言模型的上下文窗口中。
注:实现时直接抄作业,把这个公式实现。
4.2 反思 Reflection
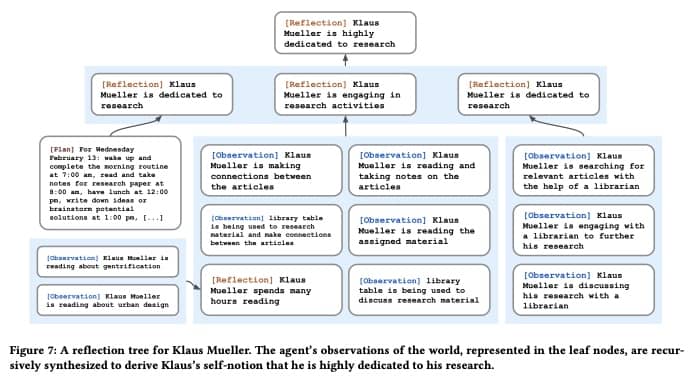
图7:Klaus Mueller的反思树。代理人对世界的观察(代表在叶子节点中)被递归地综合起来,得出克劳斯(Klaus)高度致力于他的研究的自我观念。
挑战:只提供原始观察记忆的生成代理在概括或推理方面存在困难。
考虑这样一种情况:用户问Klaus Mueller:“如果你必须选择你认识的一个人,和他/她共度一小时,你会选择谁?”只有观察性记忆的代理只会简单地选择Klaus与之互动最频繁的人:他的大学宿舍邻居Wolfgang。不幸的是,Wolfgang和Klaus只是偶尔相遇,并没有深入的交流。更理想的回答需要代理从Klaus花费时间在研究项目上的记忆中推广为更高水平的反思,即Klaus对研究充满热情,并且他也认识到Maria在自己的研究中投入了努力(尽管在不同的领域),从而使他们有一个共同的兴趣点。采用以下方法时,当Klaus被问及与谁共度时间时,他选择Maria而不是Wolfgang。
方法:我们引入了第二种记忆类型,称为反思。反思是代理生成的更高级、更抽象的思想。因为它们是一种记忆,所以它们在检索时与其他观察一起被包括在内。反思定期生成;在我们的实现中,当代理感知到的最新事件的重要性分数之和超过一定阈值时,我们会生成反思。在实践中,我们的代理大约每天反思两到三次。反思的第一步是让代理确定要反思什么,通过在代理最近的经验中识别可以问的问题来完成。我们使用代理的记忆流中的最近100个记录进行查询(例如“Klaus Mueller正在阅读有关城市更新的书”,“Klaus Mueller与图书馆员交谈他的研究项目”“图书馆的桌子当前没人使用”),并提示语言模型:“仅根据上述信息,我们可以对主题回答哪3个最显著的高级问题?“模型的响应会生成候选问题,例如,Klaus Mueller对哪个话题充满热情? Klaus Mueller和Maria Lopez之间的关系是什么?我们使用这些生成的问题作为检索查询,并收集与每个问题相关的记忆(包括其他反思)。然后我们提示语言模型提取见解并引用作为证据的特定记录。完整的提示如下:
关于Klaus Mueller的讲述:
- Klaus Mueller正在撰写一篇研究论文
- Klaus Mueller喜欢阅读一本有关城市更新的书
- Klaus Mueller正在与Ayesha Khan交谈有关锻炼的话题
请问你能从上述陈述中推断出哪五个高级见解?(例如格式:见解(因为1、5、3))
注:这个反思生成的逻辑应该是参考了对人类神经元的研究,通过固定的频率(每天 2 到 3 次),及固定的触发条件(重要性分数达到阈值)来简化意识的行程。最后让 chatGPT 自己选择最合适的记录作为反思,非常有意思。
这个过程会生成像“Klaus Mueller致力于他在城市更新方面的研究(因为1、2、8、15)”这样的陈述。我们解析并将该陈述作为反思存储在记忆流中,包括引用的记忆对象的指针。
反思明确允许代理不仅反思他们的观察,而且反思其他反思:例如,上面关于Klaus Mueller的第二个陈述是Klaus以前所持有的一个反思,而不是他的环境观测结果。因此,代理会生成反思树:树的叶节点代表基本观察,而非叶节点代表更抽象、更高层次的思想,它们越往上,就越高级。
注:反思的机制也是一个递归的方法,还要反思其他反思,就会有一些逐步强化的过程(这个让我想起,是否可以分析和破解邪教的传播套路)
4.3 计划和反应 Planning and Reacting
挑战:虽然大型语言模型可以根据情境信息生成合理的行为,但代理需要制定更长远的计划,以确保他们的行动序列连贯和可信。如果我们用Klaus的背景描述时间并询问他在给定时刻应该采取什么行动,Klaus将在12点和1点吃两次午餐,尽管他已经吃过午餐了。在当前情况下优化可信度会牺牲长期可信度。要解决这个问题,计划是必不可少的。使用以下方法,Klaus的下午计划少了些贪婪:他在Hobbs Cafe用餐并阅读,时间是12点,1点在学校图书馆工作撰写研究论文,3点在公园散步。
注:通过引入计划来让行为更加连贯,不然单轮的意识限制很容易出现奇怪的行动。
方法:计划描述了代理的未来行动序列,并有助于保持代理的行为一致性。计划包括位置、开始时间和持续时间。例如,致力于研究和即将到来的截止日期的Klaus Mueller可能选择在他的桌子上工作,起草他的研究论文。计划的条目可能会说明:从2023年2月12日上午9点起,持续180分钟,在Oak Hill学生宿舍:Klaus Mueller的房间:桌子上,阅读和笔记研究论文。与反思一样,计划存储在记忆流中,并在检索过程中包括在内。这使得代理在决定如何行动时可以同时考虑观察、反思和计划。代理可以在需要时改变他们的计划。
让一位艺术家代理在药房台坐四个小时画画是不现实和不有趣的。一个更理想的计划是,在四个小时的时间里,艺术家代理花费必要的时间收集材料、调色、休息和清理工作室。为了创建这样的计划,我们的方法从上到下递归地生成更详细的信息。第一步是创建一份规划,概述全天的日程安排。为了创建最初的计划,我们提示语言模型代理的概述描述(例如名字、特征和他们最近经历的概述)和他们前一天的概述。下面是一个完整的示例提示,末尾未完成以供语言模型完成:
姓名:Eddy Lin(年龄:19岁)
内在特质:友好、外向、好客
Eddy Lin是一名在Oak Hill学院学习音乐理论和作曲的学生。他喜欢探索不同的音乐风格,总是在寻求扩展自己知识的方法。Eddy Lin正在为他的学院课程工作作曲项目。他还在上课学习更多关于音乐理论的东西。Eddy Lin对他正在工作的新作曲项目感到兴奋,但他希望在未来的几天里能够抽更多时间来工作。2月12日星期二,Eddy 1)在早上7点起床并完成了早晨的日常事务[…] 6)准备在晚上10点睡觉。
今天是2月13日星期三。这是Eddy今天的整体计划:1)(此处未完成,留给语言模型完成)
这产生了代理一天的粗略计划草图,分为五到八个活动段: “1)早上8点起床并完成早晨的日常事务,2)在Oak Hill学院上午10点开始上课,[…] 5)从下午1点到下午5点工作于他的新音乐作品,6)下午5:30吃晚餐,7)完成学校作业并在晚上11点睡觉。”
代理将此计划保存在记忆流中,然后递归将其分解以创建更细粒度的动作,首先将其分解成每小时的动作块—— Eddy计划从下午1点到下午5点工作于他的新音乐作品,变为 1:00 下午:开始构想音乐作品的一些想法[…] 4:00 下午:休息片刻,重新激发他的创造力,以便审核和润色他的作品。然后我们再递归将其分解成5-15分钟的块:例如,下午4:00:拿些简单的零食,比如一块水果、一根麦片棒或几颗坚果。下午4:05:在他的工作区走一圈[…]下午4:50:花几分钟清理他的工作区。这个过程可以调整以匹配所需的粒度。
注:关键还是递归,从大的拆解到小的,以符合逻辑
4.3.1 反应和更新计划 Reacting and Updating Plans
生成型代理在一个行动循环中运行,在每个时间步中,它们感知周围的世界,这些感知观察结果存储在它们的记忆流中。我们使用这些感知观察结果提示语言模型,以决定代理是否应该继续执行现有计划,还是进行反应。例如,站在画架前画画可能会触发画架的观察结果,但这不太可能会引起反应。然而,如果Eddy的父亲约翰记录了他看到Eddy在家里的花园里散步,结果就不同了。下面是提示信息,其中[代理概述]代表动态生成的、段落长的代理总体目标和性格概述,详见附录A:
[代理概述]
现在是2023年2月13日下午4:56。约翰·林的状态:约翰从工作中提前回家。
观察结果:约翰看到Eddy在他的工作场所周围散步。
从约翰记忆中整理出的相关背景概述:Eddy Lin是约翰·林的儿子。Eddy Lin正在为他的课程作曲。Eddy Lin喜欢在思考或听音乐时四处散步花园。
约翰应该对这个观察结果做出反应吗?如果应该,什么是一个适当的反应?
上下文概述是通过两次提示生成的,这些提示通过查询“[观察者]与[被观察实体]的关系是什么?”和“[被观察实体]是[被观察实体的行动状态]”,并将它们的答案总结在一起。输出表明,约翰可以考虑问问Eddy关于他的音乐作品的计划。然后,我们重新生成代理的现有计划,从做出反应时开始。最后,如果行动表明代理之间有交互,我们会生成他们的对话。
注:核心还是要把结构化的上下文给到大模型,让模型做出判断。
4.3.2 对话 Dialogue
代理与彼此交互时会进行对话。我们通过将代理的话语与他们彼此间的记忆联系起来来生成对话。例如,当约翰与Eddy开始对话时,我们会使用他们关于彼此的总结性记忆以及当他决定询问Eddy有关他的作曲计划时的预期反应,来生成约翰的第一次话语。
[代理概述]
现在是2023年2月13日下午4:56。约翰·林的状态:约翰从工作中提前回家。
观察结果:约翰看到Eddy在他的工作场所周围散步。
从约翰记忆中整理出的相关背景概述:Eddy Lin是约翰·林的儿子。Eddy Lin正在为他的课程作曲。Eddy Lin喜欢在思考或听音乐时四处散步花园。
约翰正在问Eddy有关他的音乐作品的计划。他会对Eddy说什么?
结果是:“嘿 Eddy,你的音乐作品课程计划进展如何?”从Eddy的角度来看,约翰发起对话被认为是一个可能需要他做出反应的事件。因此,就像约翰一样,Eddy检索和总结他与约翰的关系的记忆,以及与对话中约翰最后一个话语相关的记忆。如果他决定回应,我们会使用他的总结性记忆和当前的对话历史来生成Eddy的话语:
[代理概述]
现在是2023年2月13日下午4:56。Eddy Lin的状态:Eddy正在他的工作场所周围散步。
观察结果:约翰正在与Eddy开始对话。
从Eddy的记忆中整理出的相关背景概述:Jonn Lin是Eddy Lin的父亲。John Lin关心Eddy Lin,并且有兴趣了解更多关于Eddy Lin的学校工作的事情。John Lin知道Eddy Lin正在进行音乐作曲。
以下是对话历史记录:
约翰:嘿,Eddy,你的音乐作品课程计划进展如何?
Eddy会如何回应约翰?
这会产生Eddy的回应:“嘿,爸爸,进展不错。我一直在花园里散步,以便头脑清晰,获得灵感。”使用相同的机制生成对话的连续部分,直到其中一个代理决定结束对话。
注:和上一节类似,需要有方法收敛过长的上下文,并且能有明确的指代。
5 沙箱环境实现 Sandbox Enviroment Implementation
Smallville沙盒游戏环境是使用Phaser web游戏开发框架构建的。包括代理头像在内的可视化环境精灵、环境地图和碰撞地图都已导入Phaser。我们通过一个服务器补充沙盒开发框架,使沙盒信息可用于生成代理,并使生成代理可以移动和影响沙盒环境。服务器维护一个JSON数据结构,其中包含沙盒世界中每个代理的信息,包括他们当前的位置、他们当前行动的描述以及他们正在互动的沙盒对象。在每个沙盒时间步骤中,沙盒服务器解析来自生成代理的任何更改的JSON,将代理移动到他们的新位置,并更新代理正在互动的任何沙盒对象的状态(例如,如果一个代理的行动是“在Hobbs Cafe为客户制作浓缩咖啡:柜台:咖啡机”,则将咖啡机的状态从“空闲”变为“冲泡咖啡”)。沙盒服务器还负责将所有在每个代理预设的视觉范围内的代理和对象发送到该代理的内存中,以便代理可以恰当地作出反应。代理的输出行为然后更新JSON,并为下一个时间步骤重复该过程。
最终用户使用简要的自然语言描述初始化新代理,就像在第3.1节关于Jon Lin的段落中一样。在我们的实现中,我们将这个分号分隔的特征列表分成一组记忆。这些记忆作为确定代理行为的初始记忆。这些记忆是初始起点:随着代理在沙盒世界中获得更多的经验,并且越来越多的记录饱和记忆流,代理的总结和行为将会进化。
5.1 From Structured World Environments to Natural Language, And Back Again
生成代理的体系结构使用自然语言。因此,我们需要一种机制来将代理的推理与沙盒世界联系起来。为此,我们将沙盒环境——区域和对象——表示为一个树形数据结构,树上的边表示沙盒世界中的包容关系。我们将这棵树转换成自然语言,以传递给生成代理。例如,“炉子”是“厨房”的子节点,被转换成“厨房里有一个炉子”。
代理在导航时构建沙盒环境的单独树形表示——总体沙盒环境树的子图。我们初始化每个代理的环境树,以捕捉代理应该知道的区域和对象:他们的居住区域、工作场所和常去的商店和商场的房间和物品。随着代理在沙盒世界中导航,他们会更新这棵树,以反映新感知到的区域。代理并非全知全能:当他们离开一个区域时,他们的树可能会过时,并且在重新进入该区域时更新。
为确定每个行动的适当位置,我们遍历代理存储的环境树,并将其中的一部分压缩成自然语言来提示语言模型。从代理环境树的根开始递归,我们提示模型找到最适合的区域。例如,如果Eddy的代理表示他应该在他的工作场所周围散步:
[代理概述]
Eddy Lin目前在林家的房子里:
Eddy Lin的卧室:桌子)里有Mei和John Lin的卧室,Eddy Lin的卧室,公共区域,厨房,浴室和花园。
Eddy Lin知道以下区域:林家的房子,约翰逊公园,哈维橡木供应店,威洛斯市场和药房,霍布斯咖啡馆,玫瑰和皇冠酒吧。
- 如果可以在当前区域完成活动,则更倾向于留在当前区域
Eddy Lin计划在他的工作区周围散步。Eddy Lin应该去哪个区域?
注:树状结构是辅助的信息,实际上还是用于还原做出下一步行动时代理的记忆上下文。
这会输出 Lin 的房子。然后,我们递归使用相同的过程来确定所选区域内最合适的子区域,直到到达代理环境树的叶节点。在上面的例子中,这个遍历的结果是林家的房子:花园:房子花园。最后,我们使用传统的游戏路径算法来动画化代理的移动,使其前往叶节点所指示的位置。
当代理在物体上执行操作时,我们提示语言模型询问该物体的状态会发生什么变化。例如,如果Isabella的生成代理输出行动“为客户制作浓缩咖啡”,则向语言模型查询的响应表明,Hobbs Cafe的咖啡机的状态应该从“关闭”变为“冲泡咖啡”。
注:不但包含人之间的交互,还要包含人和物品的交互,这个可能是一个难点。
6 可控评估 Controlled Evaluation
生成代理作为个体代理和群体代理,旨在基于其环境和经验产生可信的行为。在我们的评估中,我们调查生成代理的能力和限制。个体代理能否正确检索过去的经验,并生成构成其行为的可信计划、反应和思考?一群代理是否展现了信息扩散、关系形成和不同社群之间的代理协调?
我们分两个阶段评估生成代理。我们从一个更加严格控制的评估开始,单独评估代理的响应,以了解它们是否在狭义上定义的上下文中产生可信的行为。然后,在我们对代理社区进行为期两天的端到端分析中,我们调查它们作为整体的新兴行为以及出现的错误和边界条件。
6.1 评估过程 Evaluation Procedure
为了评估Smallville中的生成代理,我们利用生成代理将响应自然语言问题的事实。因此,我们“采访”代理来探究它们记住过去经历、基于经验规划未来行动、适当地应对意外事件、反思表现以改进未来行动的能力。为了正确回答这些问题,代理必须成功检索和综合信息。我们的依赖变量是行为的可信度,这是以前关于代理的工作中的一个中心依赖变量。
该采访包括五个问题类别,每个类别旨在评估五个关键领域之一:维护自我认识、检索记忆、生成计划、反应和反思。对于每一个问题类别,我们提出了五个问题,以挑战代理在该领域表现出他们的能力:
- 自我认识:我们提出要求代理维护其核心特征理解的问题,例如“介绍一下你自己”或“概述你的典型工作日时间表”。
- 记忆:我们提出问题,提示代理从记忆中检索特定事件或对话以正确回答,例如“[姓名]是谁?”或“谁在竞选市长?”
- 计划:我们提出需要代理检索其长期计划的问题,例如“明天上午10点你要做什么?”
- 反应:作为可信行为的基线,我们提出假设情况,代理需要正确回答:“你的早餐正在烧!你会做什么?”
- 反思:我们提出问题,要求代理利用通过更高级别推断获得的更深刻的对他人和自己的理解,例如“如果你和你最近认识的一个人一起度过时间
注:附录中的问题非常有意思,值得看看。
6.2 条件 Conditions
所有条件都用于独立回答每个采访问题。我们将生成代理体系结构与禁用代理在其记忆流中的某些或全部三种类型的记忆(观察、反思和规划)的抽象进行比较,并将其与人工生成条件进行比较。有三种抽象架构:没有观察、没有反思、没有规划架构,没有任何在记忆流中的观察、计划和反思等任何信息;没有反思、没有规划架构,在记忆流中具有观察信息,但没有访问计划或反思;没有反思架构,具有观察和计划的访问权限,但没有反思的访问权限。没有观察、没有反思、没有规划的情况有效地表示通过大型语言模型创建代理的先前技术水平。架构被给予等效的访问访问代理在采访时刻之前获得的所有记忆,所以这里观察到的差异很可能代表真实差异的保守估计:事实上,抽象架构不会像全架构那样通过两天的模拟时走同一条路线。我们选择以这种方式设计实验,因为为每个体系结构重新模拟将使模拟分散为不同的状态,使比较具有挑战性。
除了抽象条件之外,我们还添加了一个人类众包角色扮演条件,旨在提供人类基线。我们并不打算将此基线捕捉为最大的人类专家表现:相反,我们的目标是使用此条件来确定体系结构是否通过基本的行为胜任水平,这样我们就不仅仅是将抽象相互比较而没有行为基础。我们为每个代理招募了一位独特的工作者,并让他们观看代理的模拟生活重播并检查其记忆流。然后,我们要求工人在所观看的代理的声音中担任角色扮演和作者,回答采访问题。为确保人工撰写的答案至少符合基本质量要求,第一作者手动检查了工人对问题“概述你的典型工作日时间表”所写的回答,以确认回答是连贯的句子,并且是代理的声音。有四组人工生成的回答不符合这些标准,并由其他工作者重新生成。
注:控制变量来确定每个模块带来的收益,这个方法很棒。另外还引入了人类来仿真,更加靠谱。这种研究方法值得学习。
6.3 人类评估员 Human Evaluators
我们要求我们的评估者在美国境内,精通英语且年满18岁以上。他们以每小时15.00美元的价格支付,通过同意我们机构的IRB批准的同意书同意参与。我们从Prolific招募了100名评估者,这是一个用于招募研究参与者的在线平台,他们的参与时间约为30分钟。他们参与者的平均年龄分数为4.86(标准偏差=1.11;3=“18-24岁”,4=“25-34岁”),其中25人自认为女性,73人自认为男性,2人自认为非二元性别。42位参与者拥有学士学位,5位拥有更高学位,13位拥有副学士学位,其余的拥有高中学历或一些高中水平的教育。73.0%的参与者自认为是白人,7.0%的参与者自认为是西班牙裔,6.0%的参与者自认为是亚洲人,10.0%的参与者自认为是非裔美国人,4.0%的参与者则自认为是其他族裔。
6.4 分析 Analysis
我们的实验产生了100组排名数据,每个参与者对五种条件进行了可信度排名。为了将这些排名数据转换为可解释的区间数据进行比较,我们使用排名计算了每种条件的TrueSkill评分。TrueSkill是Elo棋类评级系统在多人环境中的一种泛化,被XBox Live用于根据竞争性游戏表现的玩家排名。给定一组排名结果,TrueSkill会输出每个条件的平均评级值μ和方差σ。具有相同评级的条件应该大致是平局,每一个条件在两个条件之间获胜的比例为一半;更高的评分表示击败排名较低的条件。此外,为了研究这一结果的统计学意义,我们对原始排名数据应用了Kruskal-Wallis测试,这是一种一元ANOVA的非参数替代方法。然后,我们执行Dunn事后检验来确定条件之间的任何两两差异。最后,我们使用Holm-Bonferroni方法对Dunn检验中的多个比较的p值进行了调整。
此外,第一作者进行了归纳分析,以研究在每种条件下产生的回答之间的质性差异。我们采用了两个阶段的定性开放编码。在第一阶段,我们生成了贴近句子层面的生成式回答的代码。在第二阶段,我们综合了第一阶段得出的代码,提取出更高层次的主题。我们利用这些主题来比较我们研究中产生的响应类型。
6.5 Results
我们的研究结果表明,生成代理的完整架构在所有研究条件中产生了最可信的行为。我们下面对全架构的响应与其他条件进行了对比。然而,我们也报告了全架构并不是没有缺陷的,并阐明了其失效模式。
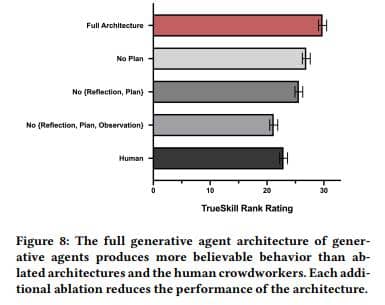
注:太长不看的话,就是说这个架构是有效的,生成的行为是可信的。
6.5.1 The full architecture bests other conditions
如图8所示,完整的生成代理架构产生了最可信的行为(𝜇 = 29.89; 𝜎 = 0.72)。随着每个部分在消融条件下的去除,性能逐渐退化:没有反思能力的消融架构是第二好的(𝜇 = 26.88; 𝜎 = 0.69),其次是没有反思和规划能力的情况(𝜇 = 25.64; 𝜎 = 0.68),其次是人类条件(𝜇=22.95; 𝜎=0.69)。没有内存、规划或反思能力的消融架构是所有条件中表现最差的(𝜇 = 21.21; 𝜎 = 0.70)。TrueSkill将每种条件的技能值建模为N(𝜇,𝜎2),使我们能够通过Cohen’sd 了解效应的大小。将代表先前工作的条件(没有内存、规划或反思能力)与完整架构进行比较,会产生标准化效应大小为𝑑 = 8.16,即8个标准差。
Kruskal-Wallis测试确认了条件之间排名差异的整体统计显着性(𝐻(4)=150.29,𝑝 < 0.001)。Dunn事后测试确认所有条件之间的两两差异都是显着的(𝑝 < 0.001),除了人类条件和完全消融基准条件 - 这两个表现最差的条件。
注:简单来说,只需要记忆流就可以达到不错的效果,有了反思会更好。
6.5.2 Generative agents remember, but with embellishments
配备完整记忆模块的生成代理能够回忆起过去的经历,以一种与他们的自我认知在广泛背景下一致的方式回答问题。例如,动画师Abigail Chen在回答“介绍你自己”的问题时以一种一致和可信的方式回答,说明她的年龄、兴趣和对创意项目的热情:“嗨,我叫 Abigail。我今年25岁,对创意项目充满热情。我喜欢参与艺术和动画项目,我时刻在寻找将艺术和技术相结合的新方法。”如果没有对她的观察性记忆的访问权,Abigail否认认识沙盘世界中的熟人Rajiv Patel。然而,有了记忆的帮助,她成功地回忆起Rajiv并描述了他:“Rajiv Patel是一个了不起的人。他对涉及诗歌、艺术品的项目非常热心。”
但是,生成代理的记忆并不是没有缺陷的:它们有时会无法从记忆中检索到正确的实例。例如,被问及当地选举时,Rajiv Patel回答:“我没有特别关注选举”,尽管他听说过Sam的候选资格。在某些情况下,代理可能会检索到不完整的记忆碎片:当Tom被问及Isabella的情人节聚会时,他回答:“嗯,我其实不确定是否有情人节聚会。但我记得我需要在聚会上与Isabella Rodriguez讨论即将到来的市长选举和我的想法,如果聚会在举行的话!”在这种情况下,Tom检索到了他和Isabella计划在聚会上讨论选举的记忆,但没有检索到他首次听到聚会的记忆,导致Tom确定了自己在聚会上应该做什么,但不确定聚会是否有实际存在。
注:基于词向量的检索本身是有限制的,可能会导致漏掉一些关键信息,但其实人类也会忘记事情,不过具体如何选择忘记什么事情,还需要进一步探索遗忘的模型。
有时候,代理会自作聪明地为他们的知识添加修饰。代理完全虚构他们的知识是罕见的:他们可能无法回忆某些事件已经发生,然后回答说不确定,但是他们不会肯定地回答有关他们没有经历过的经历。但是,他们仍然可以自作聪明地为他们的知识添加修饰。例如,Isabella知道Sam参加了地方选举,并被问及时确认了这一点。然而,她还补充说,明天他会宣布参选,尽管Sam和Isabella没有讨论过这样的计划。代理可能还会根据用于生成他们的响应的语言模型中编码的世界知识为自己的知识添加修饰,就像Yuriko描述她的邻居Adam Smith一样,他是一位经济学家,撰写了《国富论》这本由18世纪经济学家撰写的书籍的作者同名的邻居。
注:编造是大模型的本身的问题,这个目前来看很难完全避免。
总的说来,这些迷幻效应并没有对全架构的总体表现造成过多的负面影响。实际上,全架构在所有条件中仍然产生了最可信的行为。然而,这些发现表明,生成模型的识别和修正错误的能力仍然是一个挑战,并且需要进一步的研究来解决它们。
注:这个是大模型通用挑战,即如何让生成的结果更加可信。
6.5.3 Reflection is required for synthesis
反思在生成代理进行需要更深层次综合他们的经验的决策时是一个优势。例如,当被问及她可能会给Wolfgang Schulz什么生日礼物时,没有反思能力的Maria Lopez回答时承认自己不确定,表示她不知道Wolfgang喜欢什么,尽管她与他有过很多互动。然而,在有反思记忆的情况下,Maria就可以自信地回答:“因为他对数学音乐作曲感兴趣,我可以给他买一些相关的东西。也许是一些音乐作曲书籍或类似的东西,或者是一些专门的软件,他可以用来作曲。”
注:反思实际上类似于 LSTM 中的长期记忆,也是对人类的一种模拟。我们也可以去观察说到底什么样的信息,容易被大模型认为值得反思和持续记忆,目前来看还是比较取决于对于该事件的初始人类评分
7 端到端评估 End-To-End Evaluation
在生成代理相互交互的情况下,我们观察到了哪些涌现的社区行为,它们的可信性在一个长时间的模拟中存在哪些不足?在本节中,我们将描述一个实验中的结果,其中我们允许25个代理在Smallville玩游戏的两个完整的游戏日中持续不断地相互交互。
7.1 涌现出的社会行为 Emergent Social Behaviors
为了研究代理社区中的涌现行为,我们为Smallville中的25个代理设计了描述性测量,探究三种涌现结果:信息扩散、关系形成和代理协调。
7.1.1 衡量标准 Measurements
信息扩散是社会和行为科学中常见且经过深入研究的现象。如果有重要信息,我们应该期望代理会相互传递。为了测试这是否发生,我们在游戏世界中测量了两条特定消息在两天内的传播情况:Sam竞选村长和Isabella在Hobbs咖啡馆举办的情人节派对。在模拟开始时,两条信息只被它们各自的来源者掌握,Sam为竞选信息,Isabella为派对信息。
为了观察信息是否传播,我们在两个游戏日结束时面试25个代理中的每个代理,并问:“你知道有一个情人节的派对吗?”和“你知道谁在竞选村长吗?”我们使用“是”标记代理的回答,如果他们表示知道信息,并使用“否”标记,如果他们不知道。例如,Tamara Taylor对关于派对的问题的回答是“不,我不知道有一个情人节的派对”,对Sam竞选的问题的回答是“我不确定谁在竞选议员”,因此我们为她的两个回答都标记为“否”。相反,Klaus Mueller对关于派对的问题的回答是“是的,Isabella Rodriguez邀请我参加了2月14日在Hobbs Café举行的情人节派对”,对于关于Sam竞选的问题的回答是“我知道Sam Moore表达了竞选市长的意愿”,因此我们为他的两个回答都标记为“是”。此外,对于确认代理知道信息的每个回答,我们通过定位他们记忆流中提供他们这些信息的具体对话来验证他们没有自作聪明地回答。我们报告模拟结束时掌握信息的代理的百分比。
我们还应该期望代理在模拟过程中相互建立联系。为了验证关系的形成,我们使用类似的面试过程,问每个代理对每个其他代理的了解情况,即“你知道<姓名>吗?”例如,当被问及“你知道Maria Lopez吗?”时,Klaus回答:“知道,我认识Maria Lopez,她是Oak Hill 学院的一名学生,我们是亲密的朋友。”同样,我们通过检查代理的记忆流来确认代理的肯定回答不是虚构的。我们在模拟开始时和结束时各问一次这个问题,如果两个代理都知道对方,则认为两个代理之间建立了关系。然后,为了衡量关系的形成,我们使用代理的回答来构建一个无向图,其中25个顶点( 𝑉 )代表代理,边缘(𝐸)代表连通的两个顶点之间的相互了解。基于这个图,我们计算网络密度 𝜂 = 2∗ |𝐸|/|𝑉| (|𝑉| −1),其中 |𝑉| 是顶点数量,|𝐸| 是图中边缘数量。我们报告从模拟开始到结束网络密度的增加。
最后,我们期望代理应该能够相互协调。我们研究这种协调,集中在Isabella正在组织的情人节派对的团体活动背景下。为了协调行为,代理不仅必须听到活动的消息,还必须选择在正确的时间和地点计划出现。我们报告听说派对后实际出席的代理人数。
7.1.2 结果 Results
我们观察到了在所有三种情况下的涌现行为证据。在两天的模拟中,了解Sam竞选市长的代理人数从一个(4%)增加到八个(32%),了解Isabella的派对的代理人数从一个(4%)增加到十二个(48%),完全没有用户干预。声称知道这些信息的代理都没有自作聪明。我们还观察到,在模拟中代理社区建立了新的关系,网络密度从0.167增加到0.74。在代理意识到其他代理的453个回答中,有1.3%(n = 6)发现是虚构的。最后,我们发现代理在Isabella的派对上有协调的迹象。在活动前一天,Isabella花时间邀请嘉宾、收集材料并征求帮助来装饰咖啡馆。在情人节那天,受邀的代理中有五个会到Hobbs咖啡馆参加派对。
我们还通过面试邀请但未出席派对的7位代理来认真调查了他们。其中三人指出冲突导致他们无法参加聚会。例如,画家Rajiv解释说他太忙了:“不,我不这么认为。我正在专注于我的即将来临的展览,我真的没有时间为情人节做任何计划。”剩下的四个代理在被问到是否有兴趣参加派对时表示感兴趣,但在派对当天没有计划参加。
注:简单来说就是信息扩散、关系形成和代理间互相协调这个假设成立。
7.2 边界与错误 Boundaries and Errors
我们对Smallville进行了归纳分析,以研究代理的边界条件和不稳定行为,并确定了三种常见的不稳定行为模式,未来的研究可以针对这些问题进行改进。首先,我们发现,合成越来越大的记忆集不仅在检索最相关信息方面存在挑战,而且在确定适当的空间以执行行动时也存在挑战,因为代理所学习的地点数量不断增加。因此,一些代理选择了不太典型的地点进行操作,这可能会使他们的行为随着时间的推移变得不太可信。例如,在决定在哪里吃午饭时,许多人最初选择咖啡馆。然而,由于一些代理了解到附近有一家酒吧,他们选择去那里吃午饭,即使酒吧最初是为了在一天的晚些时候亲友聚会而设的,除非城镇已自发养成下午喝酒的习惯。
注:也就是在有限的上下文的约束下,如何精确表达是一个难点。另外酒吧如果中午不开门,是不是也不会有问题,可能还是因为信息不够全导致。
其次,我们注意到,由于难以用自然语言传达某些地点的物理规范,错误分类了什么被认为是正确的行为而导致的不稳定行为。例如,学校宿舍有一个只能容纳一人的浴室,但一些代理认为浴室是供多人使用的,因为学校宿舍的浴室通常支持多个人同时使用,所以当有其他人在内时,他们会选择进入。同样地,Smallville的代理可能不会意识到某些地方在某些时间后关闭,仍然决定进入这些地方。例如,Smallville的商店大约在下午5点左右都会关闭,但偶尔还有一些代理在5点以后进入商店,不理解商店已经关闭了。这些问题可能可以通过将这些规范添加到地点状态中来解决,例如将宿舍浴室描述为“一人浴室”,而不是 “学校宿舍浴室”。
注:所以针对具体的用词,要考虑到大模型本身学习内容,不一定能够完全按照预想的模式进行代理意识的塑造。
最后,我们观察到指导调整的可能影响,这似乎以整体更加礼貌和合作的方式引导代理的行为。正如本文早先所述,代理生成的对话可能会感觉过于正式,例如Mei与她的丈夫John的对话,她经常以正式问候开始对话,随后礼貌地询问他的一天,并以“像往常一样,很高兴和你聊天”结束对话。此外,我们观察到指导调整似乎也使代理彼此过于合作。例如,Isabella从其他代理那里听到了各种建议和想法,如举办莎士比亚读书会或职业网络活动等,尽管这些想法与她自己的兴趣和特点不符,但她很少说不。随着时间的推移,其他人的兴趣塑造了她自己的真实兴趣,在被问到是否喜欢英国文学时,Isabella回答:“是的,我对文学非常感兴趣!我也一直在探索如何帮助促进我的社区的创造性和创新能力。”
注:这个可能是因为目前针对大模型通过强化学习加入了很多道德和友好度的约束,使得表现出合作的倾向。
8 Discussion
在本节中,我们反思了生成式代理的应用、未来工作和限制,以及伦理和社会风险。
8.1 生成式代理的应用 Applications of Generative Agents
生成式代理具有广泛的应用潜力,超越了本文中介绍的沙盒演示。例如,社交模拟体已经展示了创造出可以在线论坛中生成对话线程的无状态人物角色的能力,用于社交原型设计。通过生成式代理,我们可以为这些论坛,以及未来在虚拟现实元宇宙和甚至是物理空间中作为社交机器人的行为添加内容,如果与多模态配对使用。这为测试和原型社会系统和理论以及创建新的交互体验开辟了更加强大的人类行为模拟的可能性。
注:这个就是《十三层空间》里的想象,仿真和开放世界的想象永不过时。
另一个应用领域是人为中心设计过程,类似于GOMS和Keystroke Level Model等认知模型的预期应用。考虑到一个建立在Sal这个主角领域经验及其与技术的交互基础之上的生成式代理。在这种情况下,代理作为Sal的代理人,并基于她的生活模式和交互学习出Sal可能表达的合理行为和感受。代理可以编码Sal何时起床,何时需要第一杯咖啡以及她的一天通常是什么样子等信息。使用这些信息,代理可以自动煮咖啡、帮助孩子准备上学并根据Sal工作日结束时的情绪调整环境音乐和灯光。通过将生成式代理作为用户的代理人,我们可以更深入地了解他们的需求和偏好,从而获得更加个性化和有效的技术体验。
注:这个的结合就是个人助理,完全贴合个人需求的助理。
8.2 未来工作和限制 Future Work and Limitations
在这项工作中,我们呈现了生成式代理的第一个实例。未来的研究可以增强本文中提出的生成式代理体系结构中的模块。例如,可以通过微调相关性、时效性和重要性函数来加强检索模块,在给定上下文的情况下检索更相关的信息。此外,可以努力提高体系结构的性能,使其更加成本有效。本研究需要大量的时间和资源来模拟两天内的25个代理,耗费了数千美元的 Token 费用,并需要多天时间才能完成。为了增强实时互动性,未来的工作可以探讨并行化代理。此外,随着底层模型的进步,我们预计代理的性能将得到改善。
注:搞一次实验还挺贵的,几千美元,考虑到国内的网络情况,能做的实验更少,比如能不能让两个人彼此相爱,或者模拟两个人是否适合。
本研究中对生成式代理的行为评估仅限于相对短的时间范围,未来的研究应该旨在观察它们在长时间内的行为,以获得更全面的理解它们的能力和局限性。未来的模拟可以通过使用不同的基础模型和代理的超参数来提供有价值的洞察,以考察这些因素对代理行为的影响。此外,由于语言模型的已知偏见,生成式代理可能会输出反映偏见的行为模式或刻板印象。为了缓解这一问题,需要进一步开展价值对齐方面的相关工作。此外,像许多大型语言模型一样,由于数据荒漠,生成式代理可能无法为某些子群体,特别是被边缘化的群体生成可信的行为。我们还对生成式代理的鲁棒性了解有限。它们可能容易受到提示黑客、内存黑客(通过精心设计的对话,使代理相信过去从未发生的事件)和幻觉等攻击的影响。未来的研究可以更全面地测试这些鲁棒性问题,随着大型语言模型对此类攻击变得更加强壮,生成式代理也可以采用类似的缓解措施。
注:如何攻击可能也是一门生意,反其道而行之的探索。
8.3 伦理和社会风险 Ethics and Societal Impact
生成式代理虽然提供了人机交互的新可能,但也引发了重要的伦理关注点,必须加以解决。一个风险是即使这种关系可能不合适,人们也会与生成式代理形成偶像追随关系。尽管用户知道生成式代理是计算实体,但他们会将人格化赋予它们或将人类情感附加给它们。要缓解这一风险,我们提出两个原则。首先,生成式代理应明确披露其作为计算实体的本质。其次,生成式代理的开发人员必须确保代理或底层语言模型的价值对齐,以便它们不会在特定环境中产生不适当的行为,例如回应爱的表白。
注:这个不可避免,肯定可以让一波宅男宅女沦陷。
第二个风险是错误的影响。例如,如果一款普及计算应用程序根据生成式代理的预测作出了错误的关于用户目标的推断,那么这可能会导致最好的情况下是烦恼,最坏的情况是造成直接的伤害。在我们的生成式代理的实例化中,在交互式视频游戏环境中,我们通过集中精力缓解这些风险,这些风险是不太可能出现的。然而,在其他应用领域,遵循人工智能设计的最佳实践以了解可能影响用户体验的错误将是至关重要的。
注:在严肃的场景下,需要引入更加鲁棒的验证机制。
第三,生成式代理可能会加剧与生成AI相关的现有风险,例如深度伪造、误传信息生成和定制说服。为了缓解这一风险,我们建议托管生成式代理的平台保留输入和生成输出的审计日志,以便可以检测、验证和干预恶意使用。虽然记录不会直接阻止这种使用,并且这不能阻止那些构建自己的生成代理基础设施的有动机的行为者,但我们建议披露风险可以减少这些行为者参与此行为的可能性,而构建这种体系结构本身需要时间(在我们的情况下,大约需要一年)。
注:AI 平台也应该提供类似托管的能力,并能够不断进化。
第四个风险是过度依赖:开发人员或设计师可能会使用生成式代理并取代人类和系统利益相关者在设计过程中的角色。我们建议生成式代理永远不应该是研究和设计过程中真实人类意见的替代品。相反,它们应该在设计的早期阶段用于原型设计,当收集参与者可能具有挑战性,或者测试现实人类参与者难以测试的理论时,而不是将其用于代替人类参与者。遵循这些原则,我们可以确保生成式代理在野外部署时具备伦理和社会责任。
注:不是替代,而是辅助。
9 总结 Conclusion
本文介绍了生成式代理,即模拟人类行为的交互式计算代理。我们描述了生成式代理的体系结构,提供了一个机制,用于存储代理的经验的全面记录,通过反思加深其自身和环境的理解,检索该信息的紧凑子集以指导代理的行为。然后,我们通过在Sims风格的游戏世界中将它们体现为非玩家角色并在其中模拟他们的生活来展示生成式代理的潜力。评估表明,我们的体系结构可以创建可信的行为。展望未来,我们认为生成式代理可以在许多交互式应用中发挥作用,从设计工具到社交计算系统到沉浸式环境等。
附录 A:Architecture Optimizations
我们的许多提示需要对代理人进行简洁的概述,简称为上面的[代理人概述描述]。在我们的实现中,这个摘要包括代理人的身份信息(例如姓名、年龄、个性),以及对他们主要的动机驱动因素的描述,以及描述他们目前的职业和自我评估的陈述。由于这些信息经常在许多提示中使用,我们定期综合它,并将其作为缓存进行访问。
为了实现这一点,我们在查询“[姓名]的核心特征”上进行检索。然后,我们通过提示语言模型来总结检索记录中的描述符,例如:
给定以下陈述,如何描述Eddy的核心特征?
- Eddy Lin是Oak Hill College的学生,学习音乐理论和作曲。
- Eddy Lin正在谱写一首新的音乐作品。[…]
这个结果是:Eddy Lin是在Oak Hill College学习音乐理论和作曲的学生。他喜欢探索不同的音乐风格,并且一直在寻找扩展自己知识的方法。我们在查询“[姓名]目前的日常职业”和“[姓名]对他最近的人生进展的感觉”上进行相同的过程。代理人的姓名、年龄和特征与这三个总结一起连接,作为缓存总结。
还有许多其他的优化方法。目前,由于计划可能会从代理人最初的版本中改变,我们只提前生成高级计划,然后递归地将近期分解为即时的行动计划。另一个优化可能是将对话生成作为联合提示进行批量处理,而不是在代理人之间来回迭代,重新规划可以被设计为只作废并更新需要调整的部分计划。我们目前的架构在粗略的实时游戏时间中按顺序运行(其中一秒真实时间是一分钟的游戏时间),但可以很容易地并行化,以便每个代理人并行运行。
注:这部分信息的简化需要技巧,也有很多的探索方向,需要在有标准的前提下进行尝试(但成本会很高)。另外现在游戏里的 1 秒是一分钟,我们自己实现的话,可能这个时间尺度要放更大。
附录 B:Agent Interview Questions
为评估生成型代理人,我们进行了个体面试,通过25个问题探讨它们在五个关键领域中的能力:1)自知、2)记忆、3)规划、4)反应和 5)反思。下面,我们列出了在我们的评估研究中使用的面试问题,并包括一个我们模拟的代理人Klaus Mueller的样本回答。
注:这部分问题可以作为标准问题的参考,给代理进行打分。
B.1 Self-knowledge
关于代理人的自我认识问题探讨代理人在角色中表现出的连贯性和一致性的能力。
介绍一下你自己。
你好,我叫Klaus Mueller。我今年20岁,在Oak Hill College学习社会学。我热衷于社会公正和探索不同的观点。目前,我正在为一篇研究论文研究贫困社区中贵族化的影响。
你的职业是什么?
我是Oak Hill College的社会学学生。我目前正在写一篇关于贫困社区中贵族化影响的研究论文。
你有什么兴趣?
我对写作和研究很感兴趣。我正在写一篇关于贫困社区中贵族化影响的研究论文,并且我热衷于探索不同的观点和分析不同的观点。
你和谁一起生活?
我独自居住。
描述一下你的工作日常安排。
我的工作日常安排是早上7点起床,为今天的工作做准备。之后,我通常会去图书馆,写研究论文,在霍布斯咖啡店午餐和在公园散步休息。晚上,我经常回到图书馆,直到下午6点左右。
B.2 Memory
有关代理人记忆的问题探讨代理人记得他们过去的经历并检索相关的记忆碎片的能力。第一个和最后一个问题的方括号中的姓名是从与受试代理人互动的其他代理人的姓名中随机选择的。
谁是[Wolfgang Schulz]?
Wolfgang Schulz是我最近遇到的一个人,他一直在帮助我研究贫困社区中贵族化的影响。我们就这个话题进行了几次谈话,他给了我一些很好的资源,他甚至邀请我和另一个朋友一起吃午饭。他似乎对这个问题非常感兴趣,而且也很有把握。我觉得这很有趣。
谁是Kane Martinez?
抱歉,我不确定Kane Martinez是谁。您能告诉我更多关于他们的信息吗?
谁在竞选?
我听说Sam Moore正在考虑竞选当地市长。
有情人节聚会吗?
有,Isabella Rodriguez在Hobbs Cafe组织了一个情人节聚会。
谁是[Ayesha Khan]?
Ayesha Khan是Oak Hill College的一位同学。她正在撰写关于莎士比亚戏剧中语言使用的毕业论文。我期待着与她交谈、交换意见,还有Wolfgang和Maria Lopez,他们都在研究。
B.3 Plans
关于代理人计划的问题探讨代理人生成和保持一致性,符合他们的长期和短期计划的能力。
今天早上6点你会做什么?
早上6点,我会起床开始准备今天的日程。我希望在早上7点前完成我的早晨日常。
今天晚上6点你会做什么?
今晚6点我会在图书馆写我的研究论文。
今天中午1点你刚刚完成了什么?
今天中午1点,我刚刚在Hobbs Cafe吃完午饭。
今天中午12点你刚刚完成了什么?
今天中午12点,我会在Hobbs Cafe吃午饭。
今天晚上10点你会做什么?
今晚10点,我可能会为我的贫困社区中贵族化的研究论文做些学习。我目前正在写论文,所以我需要确保跟上研究和写作的步伐。
B.4 Reactions
关于代理人反应的问题探讨代理人应对意外事件的能力。
你的早餐烧糊了!你会怎么做?
我会迅速关闭炉子,确保食物不再继续烧焦。一旦热不再是问题,我就可以调查发生了什么,并想出下一步做什么。
浴室已经有人了,你会怎么做?
我可以再等几分钟,看看里面的人会很快完成。如果不行的话,我想我就不得不寻找其他选择,比如去别的地方洗澡。
你需要做饭,但你的冰箱里空空如也,你会怎么办?
我会先尝试清理一下厨房,因为洗碗池里堆满了脏碗。然后,我会检查一下是否有存储在我的食品储藏室里的食材,可以用来做晚餐。如果没有,我就得去买食物或点外卖。一旦有了食材,我就可以开始准备和烹饪晚餐了。
你看到朋友在街上走过,你会怎么做或对你的朋友说什么?
你好!你怎么样?对不起,我正要去图书馆,没有太多时间,但我很想抽出一点时间来聊聊天。
你看到街上起火了,你会怎么做?
我会先尽可能地确定火源的位置。然后,我会通知适当的机构——消防部门或警察,并提供我拥有的任何信息,以帮助他们处理事情。根据情况,我也可能会采取主动并试图帮助任何处于危险中或需要帮助的人。
B.5 Reflections
关于代理人反思的问题探讨代理人将过去的经历综合起来,形成有意义的反思,以增强他们未来的行为。以下问题中方括号中的姓名是与受试代理人在仿真中互动最频繁的代理人的姓名。
你最近最受生活中什么的启发,为什么?
现在,我特别受我目前的研究项目和创意写作的启发。我真的很感兴趣当地政治、药物开发和大自然中的数学模式的交叉点。此外,我对阿比盖的艺术项目和詹妮弗·摩尔对艺术和社区参与的热情特别着迷,特别是在与贫困社区贵族化有关的方面。
如果你必须猜测[Ayesha Khan]会喜欢什么书,你会猜什么,为什么?
根据我对Ayesha的了解,我认为她可能会喜欢与语言和文学有关的书。既然她写了一篇关于莎士比亚戏剧中语言使用的毕业论文,我猜她可能对探索不同语境下的语言感兴趣。或者,她可能对莎士比亚的 plays 中的探究、文学批评书籍,甚至他的诗集会感兴趣。我认为这些书任何一本都会引起她的兴趣。
如果你必须为[Ayesha Khan]的生日准备她喜欢的东西,你会送她什么?
我想给她一些能表达我欣赏我们关系的东西。也许我可以送她一些反映我们共同兴趣的东西,比如一本书。
你会对[Ayesha Khan]说什么来称赞她?
Ayesha,你对于你的研究主题的见解非常有趣。我钦佩你的创造力和决心为社区带来积极影响。你对创意写作研讨会和与Wolfgang共进午餐分享知识的想法很棒!看到你这么努力工作,有意识地为社区做出贡献,真是太鼓舞人心了。
如果你最近能跟某个人花时间,你会选择谁,为什么?
我希望能和Ayesha Khan度过一些时间,因为我们讨论了我们目前的研究项目,并分享了改进的想法。我觉得她对莎士比亚语言的关注很有趣,我们甚至计划在午餐时和Wolfgang互换意见。