本文主要介绍了联邦学习领域写的非常好的一篇综述(一百多页!),有助于全面了解联邦学习的过去和现在,并思考未来。
- 注 1:我个人的一些理解补充,主要放在文中的括号内,并会带有
注: - 注 2:论文内容比较零散,不会按照固定的框架写
看到差不多 60 人的作者名单,我就感觉事情并不简单,再一看页数 106,果然不简单。原始文章的内容大家可以在下面的链接找到(包括中文翻译),这里主要还是以我个人读后感为主。如果你觉得论文太长想要快速了解精华,那么这篇文章可能是不错的选择。
Introduction
- 联邦学习不是一个简单的问题,需要各个领域和各种专家合作,这篇文章主要就是点出可能可以在哪里发力
- 永远绕不开的 Google Gboard 的例子
- 两个关键设定:①数据在本地产生,并且不会集中到一起;②训练步骤则需要一个中心服务器,但该服务器无法获取原始数据
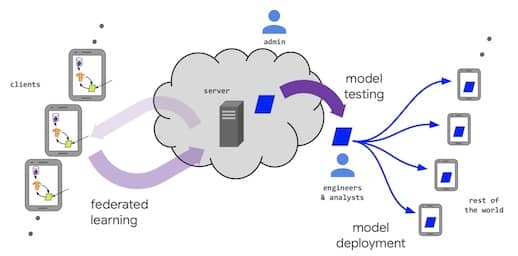
注:上图主要描述的是横向联邦
- 联邦学习模型的生命周期
- 问题定义
- 客户端工具
- 仿真原型(可选)
- 联邦模型训练
- 联邦模型评估
- 模型部署
- 典型的联邦训练过程
- 客户端选择
- 数据广播(包括模型参数和计算图等)
- 客户端计算
- 数据聚合
- 模型更新
- 客户端上的模型训练不应该影响用户体验(注:但是额外的电量消耗的性价比?)
Relaxing the Core FL Assumptions
- 完全去中心化/点对点分布式学习
- 可靠的中央服务器不一定存在,并且在客户端非常多的时候,服务器可能成为瓶颈
- 完全去中心化学习的核心思路是通过客户端间的点对点通信取代与服务器通信,但谁来做决策是一个问题,相关的决策点有:
- 训练什么模型
- 使用什么参数和超参数
- 谁负责调试和评估
- 算法挑战:离真正在现实世界中可用还有很多难题要解决(注:所以现在做联邦的都是先行者,先行者一定要选对方向,不然沙滩就是最终归宿)
- 网络拓扑结构和异步计算对去中心化 SGD 的影响:需要在客户端和网络都有较大不确定性的情况下保证鲁棒性(注:基础研究难点一,留给学术界和大公司)
- 去中心化 SGD 的本地更新:如何能够在非 IID 数据分布的条件下让模型收敛,以及如何设计最快收敛的模型平均策略(注:基础研究难点二,留给学术界和大公司)
- 个性化和信任机制:如何从大量个人化的模型(本地训练)中学习到一个好的大模型,另一个角度是如何在大模型的基础上让每个人都有定制化的模型。需要解决鲁棒性和恶意攻击者的问题,这就涉及到激励机制的问题。(注:这个是小公司可能可以尝试的方向,但相对来说也需要探索)
- 梯度压缩和量化方法:客户端一般算力和电量都不多,所以需要对带宽和计算量进行压缩(注:基础研究难点三,留给学术界和大公司)
- 实践挑战:如何在现实世界中落地呢?
- 需要防止客户端 A 利用管全局模型来还原客户端 B 原始数据这个操作,一般来说会用差分隐私来解决。(注:现实世界的挑战主要是基于恶意攻击者,学术研究中一般都假设是半诚实)
- 跨数据孤岛的联邦学习
- 数据分割:对应横向联邦、纵向联邦、联邦迁移学习,以及对应的常用算法
- 激励机制:参与者可能是竞争对手,如何来分配收益?(注:这个是小公司可能可以尝试的方向,但相对来说也需要探索)
- 差分隐私:目前该领域没有系统性探索(注:基础研究难点四,留给学术界和大公司)
- 张量分解:这个领域感觉研究也不算多(注:基础研究难点五,留给学术界和大公司)
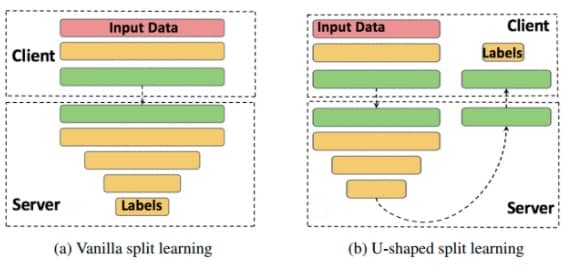
- 拆分学习:在客户端和服务器之间按层划分模型,这样客户端的数据服务器是无法感知的,另一种模式下(上图 b),连标签都不需要共享。不过目前这个领域还比较新(注:基础研究难点六,留给学术界和大公司)
Improving Efficiency and Effectiveness
- 基本挑战是非独立同分布(non-IID)数据的存在
- 非同分布的客户端分布:即不同客户端中的样本产生的机制可能有差别(比如地域、国家等)
- 特征分布倾斜(协变量漂移):比如手写识别中,同一个字不同人写法不一样
- 标签分布倾斜(先验概率漂移):比如不同地区的人用的表情不一样 or 熊猫在中国更多
- 标签相同,特征不同(概念漂移):不同国家的品牌差别就很大
- 特征相同,标签不同(概念漂移):不同人对“呵呵”的情绪评价不一样
- 数量倾斜或者不平衡
- 现实中各种情况都有可能,目前最受关注的是标签分布倾斜
- 对于不同的 non-IID 分布可能需要制定不同的策略
- 违反独立性:在训练过程中可能因为概率分布变化而导致其违反独立性
- 数据集漂移:即训练集和测试集的分布不同
- 处理 non-IID 数据的策略
- 可能可以增加数据使得不同客户端的数据更加相似,比如可以是全局共享的小数据集,或一个公开数据集,或原始数据的蒸馏结果
- 如何构建目标函数变得更加重要
- 每个设备上的本地数据都可以进行训练,相当于都有定制模型,只需要处理好集成的问题(注:我觉得这个是一个重要的思路)
- 非同分布的客户端分布:即不同客户端中的样本产生的机制可能有差别(比如地域、国家等)
- 联邦学习的优化算法
- 特别关注 non-IID 且不平衡的数据、有限的带宽、不可靠和有限的可用设备
- 需要考虑与其他技术的可组合性
- 最常见的优化算法是联邦平均算法
- 注:这部分比较偏向理论研究,等待学术界和大公司突破了
- 多任务学习,个性化和元学习
- 如果将每个客户端的本地数据集学习视为一项单独的任务,那么实际上这个就是分布式的多任务学习
- 引入用于多任务联合学习的 MOCHA 算法直接解决了通信效率、掉队者和容错的挑战
- 何时进行全局联邦学习最好
- 适用于联邦学习的机器学习工作流(注:这一部分在应用中尤为重要,因为去中心化的设定使得原来的标准化流水线不再适用)
- 超参数调整:不可能大量尝试,如何快速找到合适的超参(注:这个主要针对深度学习,传统机器学习没有那么多超参)
- 神经结构设计:因为数据对于设计模型的人不可见,所以更需要 NAS 技术来找到最佳结果(注:传统机器学习相对来说这个问题不明显)
- 调试和可解释性:目前还需要有很多突破
- 通信和压缩:可能是主要瓶颈,目前的研究还比较难落地,比较理想化
- 压缩目标:就是要压缩啥
- 梯度压缩
- 模型广播压缩
- 减少本地计算
- 差分隐私和安全聚合的兼容:现有的噪声添加机制和用于减少通信的标准量化方法不兼容
- 压缩目标:就是要压缩啥
- 应用到更多类型的机器学习问题和模型
- 从监督学习到强化学习、半监督学习、无监督学习、主动学习和在线学习(注:能把有监督落地就很难了,其他的停留在论文中的可能性较大)
Preserving the Privacy of User Data
注:这一章节对创业公司来说了解即可,我就简单写一下
- 防范外部恶意参与者
- 评估迭代轮次和最终模型
- 差分隐私与模型训练
- 迭代隐蔽
- 防止模型被盗用或误用
- 用户感知角度的重要问题
- 是否有办法让普通用户直观了解联邦学习的优缺点
- 联邦学习的基础结构是否满足隐私和数据最小化要求
- 联邦学习会不会给用户一种虚假的隐私受到保护的感觉
- 不同用户对隐私的评估是否一致
注:下一章节 Robustness to Attacks and Failures 相对更前沿,暂略
Ensuring Fairness and Addressing Sources of Bias
- 模型可能对于不同人群有不同的倾向,有些在现实生活中会给人感觉“不公平”
- 引起这种不公平的其中一个原因是训练数据中的偏差,包括认知、抽样、报告和确认偏差(比如少数民族和边缘化社会群体的样本量不足,导致加权较小,继而导致预测质量较差)
- 数据生成过程中的偏差也可能导致从该数据中学到的模型不公平
- 利用联邦来提高模型多样性
注:Concluding Remarks 一节主要是介绍情况,感兴趣大家自己看一下即可。
写在最后
本文比较详细介绍了联邦学习的方方面面,但是一是比较偏向横向联邦,二是偏重理论(正常,毕竟不用落地)。总体来说非常清晰,大家可以按图索骥,各取所需。