至此,我们已经基本拥有了大部分所需的理论知识,可以重点说一说,如何实际开展一个机器学习项目了。
更新历史
- 2019.10.18: 完成初稿
开展机器学习项目的策略
为什么说开展机器学习项目需要一定的策略呢?因为提高效果的各种方法基本都需要投入比较大的人力物力和时间,如果没有策略瞎尝试,很容易时间过去了啥成果没出来。
所以接下来我们看一些重要的策略
正交化 Orthogonalization
机器学习的假设链为:

所谓正交化,就是在这里的每个步骤,都能有对应的调整方法,而不影响其他步骤。接下来会详细介绍各种方法,这里要了解的就是这些方法尽量只对系统有单一改变,不然不好评估效果
单一数字评估指标 Single Number Evaluation Metric
常见指标有:
- 查准率 Precision
- 查全率 Recall
- F1 值
有一个单实数评估指标可以有效提高效率,因为一下就可以比较出来。接下来看看如何设计这些指标
满足和优化指标 Satisfying and Optimizing Metrics
虽然说有一个单一指标很爽,但是一般来说我们要关注的方面很多,想要组合成一个单实数并不是那么简单,比如既要考虑模型准确率,又要考虑模型运行时间的时候。
这个时候可以这样处理,其中一个最重要的指标作为优化指标(需要尽可能优化),其他的属于满足目标(只要达到一定门槛就可以)。
训练/开发/测试集划分
需要注意的核心原则:这个数据的分布应该与整体的分布接近,即足够有代表性。
具体如何划分?
首先要强调的是,七三开不再合适。现在流行的做法是大量数据作为训练集,少量数据为开发集和测试集
什么时候改变开发/测试集指标?
如果当前的指标和当前用来评估的数据和你真正关心必须做好的事情关系不大,就应该改变,让用来评估的数据更接近实际。这些数据集和评测指标的建议能够让整个团队设立一个明确的目标,一个可以高效迭代,改善性能的目标。
为什么要跟人比?
主要原因如下:
- 人类水平在很多任务中离贝叶斯最优错误率已经很接近了
- 在人类水平之下,有不少工具可以提高性能,但在人类水平之上,这些工具就没有那么有效
可避免偏差 Avoidable bias
假如对于一个任务来说,人类的错误率是 1%,而算法达到的是 8% 的训练错误率和 10% 的开发错误率,那么说明这个算法还不够好,我们的重点是减少偏差(就是降低训练错误率)。比如训练更大的神经网络,或运行更久的梯度下降。
但在另一种情况,如果人类的错误率是 7.5%,而算法达到的是 8% 的训练错误率和 10% 的开发错误率,那么说明这个算法已经可以了,我们的重点是减少方差(缩小开发错误率和训练错误率的差距)。比如尝试正则化或 Batch Normalization。
定义一下,贝叶斯错误率(理论最优)与训练错误率的差,就是可避免偏差,意思是算法还能提高的偏差。
而我们在人类表现良好的任务中,一般会用人类的表现,来作为贝叶斯错误率的一个近似。
另外再提一句,在超过人类的表现之后,因为不太好确定可避免偏差对模型的影响大还是方差对模型的影响大,所以需要花更多的事情去判断和探索,一般来说进展会变慢。
改善模型表现 Improving Model Performance
我们现在组合前面学到的东西,给出一套完整的提高学习算法性能的指导方针。
两个基础前提:
- 算法在训练集上表现良好 -> 低偏差
- 训练集得到的模型,在开发集和测试集上表现也很好 -> 低方差
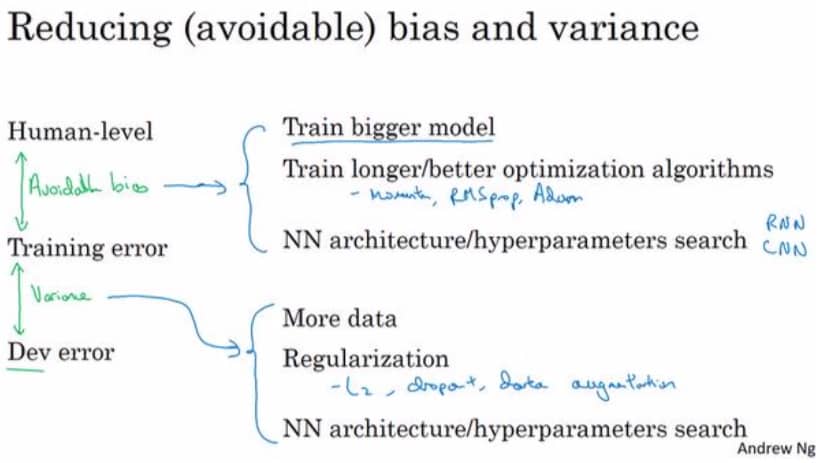
对应的,为了解决偏差高的问题,可以尝试如下策略:
- 使用规模更大的模型
- 使用更好的优化算法,比如 RMSprop 或 Adam
- 寻找更好的神经网络架构,更好的超参数(改变激活函数、层数、每层单元数)
- 使用其他模型架构,如 CNN 或 RNN 等
为了解决方差高的问题,可以尝试如下策略:
- 收集更多数据
- 正则化(L2, Dropout, 数据增强)
- 不同的神经网络架构
- 超参数搜索
把两种合到一起,可以参考下图:
进行误差分析 Carrying out Error Analysis
进行错误分析,应该找一组错误样本,看看假阳性(false positives)和假阴性(false negatives)的特点并统计不同错误类型的错误数量。在这个过程中,我们可能会得到启发,归纳出新的错误类型。通过比较不同错误类型的百分比,我们可以确定优先解决的错误类别。
清除标注错误的数据 Cleaning up Incorrectly Labeled Data
深度学习算法可以比较好处理随机误差,但是如果一直把近似的数据标准错误,相当于数据被污染,模型很容易学“歪”。
我们需要关注三个数据,来评估是否需要清除标注错误的数据。假如系统整体准确度是 90%,即 10% 的错误率,如果 6% 的错误来自标注错误,也就是说会影响 0.6% 的整体准确率,那么我们应该着力去关注其他 9.4% 的错误。
但如果错误率为 2%,标注错误对总体准确率影响同样是 0.6%,那么比例就大大改变,变成 0.6% 比 1.4%,这个时候修复标注数据的错误就很有价值了。
虽然看错误数据很花时间很无聊,但从统计数据中确实可以明确下一步努力的方向,是一个事半功倍的操作。
快速搭建系统并进行迭代
一般来说,对于任何一个机器学习程序来说,都有几十种不同的方向可以去尝试,问题在于,要选哪个方向?
但与其纠结太多,不如直接开搞。设定好训练集、开发集和测试集,然后就在实践中摸索最佳方向,不必担心一开始表现不佳(这几乎是必然的),重点在于我们可以从中了解未来的方向并不断前进。
当然了,如果已经有相关论文,那也值得看看,从他人的经验中学习。
数据分布不同时的偏差和方差 Bias and Variance with Mismatched Data Distributions
如果训练集和开发、测试集的分布不同,分析偏差和方差的方式也需要有一定的变化。
原来的数据划分为:
- 训练集 1000000 条(来自分布 A)
- 开发集 100000 条(来自分布 B)
- 测试集 10000 条(来自分布 B)
使用训练集训练模型后,训练误差 1%,开发集误差 10%。但是因为来自两个不同的分布,我们现在无法直接下结论新增的 9% 的误差是来自算法,还是来自数据。我们可以改变一下数据划分,增加一个数据集,如下:
- 训练集 900000 条(来自分布 A)
- 训练-开发集 100000 条(来自分布 A,就是前面训练集的一部分)
- 开发集 100000 条(来自分布 B)
- 测试集 10000 条(来自分布 B)
再次重复训练和验证,训练误差 1%,开发集误差 10%,而训练-开发集的误差是 9%,那么这就说明算法存在方差高的问题,因为训练集和训练-开发集来自同一分布,就可以按照之前的方法来进行判断。
而如果训练误差 1%,开发集误差 10%,而训练-开发集的误差是 1.5%,那么说明方差问题很小,于是就变成了数据不匹配问题,简单来说就是开发集的数据,模型没见过,所以不懂。
定位数据不匹配 Addressing Data Mismatch
很遗憾,数据不匹配问题并没有一个系统的解决方案。一个比较好的入手方法做错误分析,人工查看训练集和开发测试集的差异。找到差异后,可以用人工数据合成的方式快速制造徐两年数据,然后再次进行训练(但是注意了,这个方法很容易过拟合)
迁移学习 Transfer Learning
简单定义下就是从一个任务中学会的东西,可以用到另一个任务上。一般来说套路是这样的:
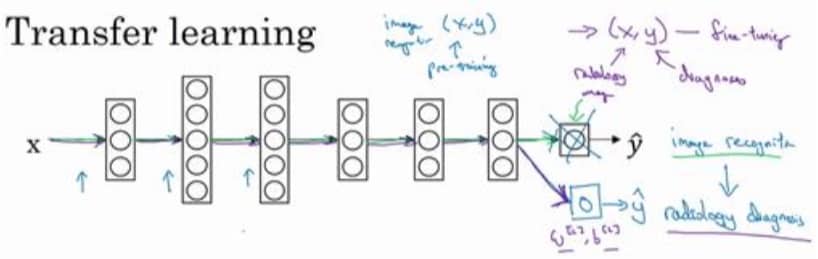
我们保留除最后一层之外的所有网络结构和参数,重新加一个输出节点,然后用新的数据集只训练这个新的节点的参数。前面的网络参数已经确定,称为预训练(pre-training),我们只修改部分的节点,称为微调(fune tuning)。
当然,迁移学习也不是万能的,是有一定条件的,条件如下:

多任务学习 Multi-task Learning
简单来说,就是同时让一个神经网络做多个事情,而这些不同的事情是有一定关联,可以相互辅助的,比如研发无人驾驶时检测行人、车辆、标牌等。多任务学习的网络结构如下:
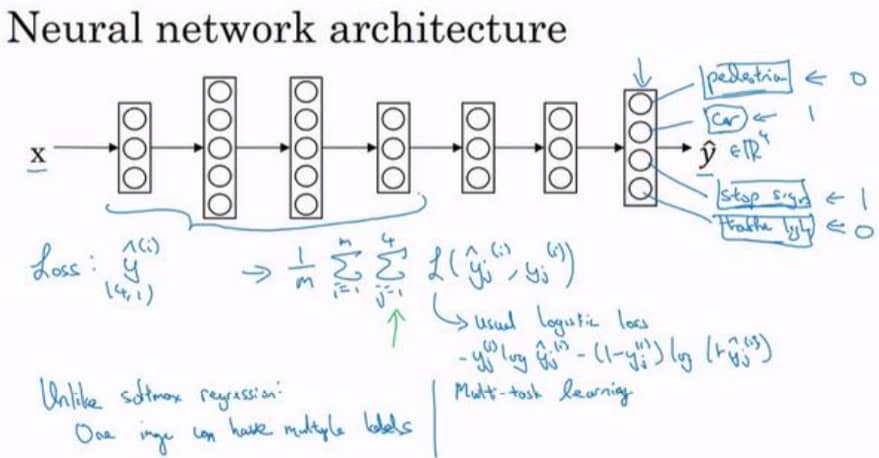
还是用无人驾驶举例子,最后输出节点不再是一个,而是四个,可以分别判断有没有行人、车、停车标志和交通灯。因为输出变成了四个,所以我们的损失函数也需要变化,整个训练集的平均损失现在是:
公式里的 L 就是 Logistic 损失,这里不再重复打公式了。
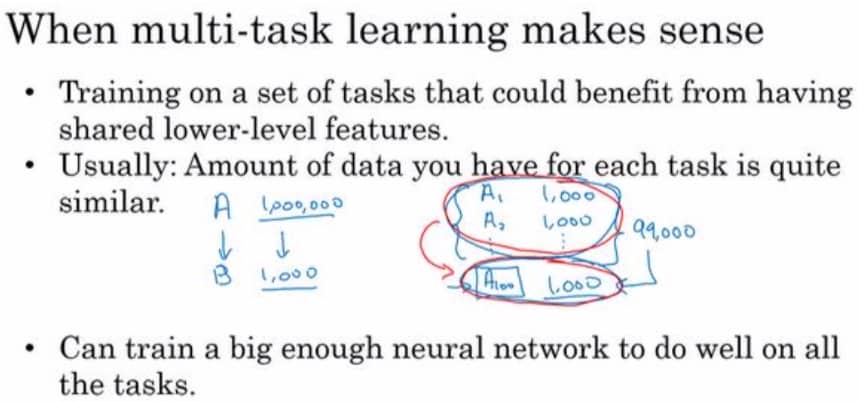
和迁移学习一样,多任务学习也是有条件的,具体如下:
端到端深度学习 End-to-End Deep Learning
之前做机器学习,一般需要特征工程+模型训练等等步骤才能得到最终结果。但是端到端则不用这么复杂,只要给出足够多的数据,就可以得到不错的效果。不过这里的足够多,是真的非常多才可以,远大于传统方式。
不过需要注意的是,不同的问题场景,有不同的解决方法,端到端并不是万能的,但是在某些领域,比如机器翻译,端到端的方法效果很好。
端到端的优点
- 让数据本身说话
- 比较少需要人工设计的组件
端到端的缺点
- 需要非常大量的数据
- 排除了哪些可能有用的人工设计的组件(无法利用已有经验)