上节课我们了解了 CNN 的基本原理和经典网络,这节课我们就用 Tensorflow 来尝试构建一个 CNN 模型。
更新历史
- 2019.08.14: 完成初稿
Convolution 卷积
卷积的定义这里不再赘述,大家只要知道是一种矩阵运算即可,更多相关的内容可以参考 这里。因为卷积实际上是一个确定的数学运算,我们只要设置好 filter,直接计算就可以看到效果。
在 Tensorflow 中,已经提供给我们几种内置的卷积方法(1 维卷积输入是 2 维,2 维卷积输入是 3 维,更多详细的说明可以参考 这里)
参考代码 16_basic_kernels.py,我们直接用预置的权重来处理图像,大家可以看看不同的效果。我自己找了一张图效果如下:

Convnet on MNIST
接下来我们详细说明一下如何用 CNN 进行 MNIST 手写数字识别,具体代码参考 17_conv_mnist.py
我们构建的网络如下图所示:有 2 个卷积层,每个都跟着一个 maxpool 池化层,最后是两个全连接层,所有卷积层的步长都是 [1,1,1,1]
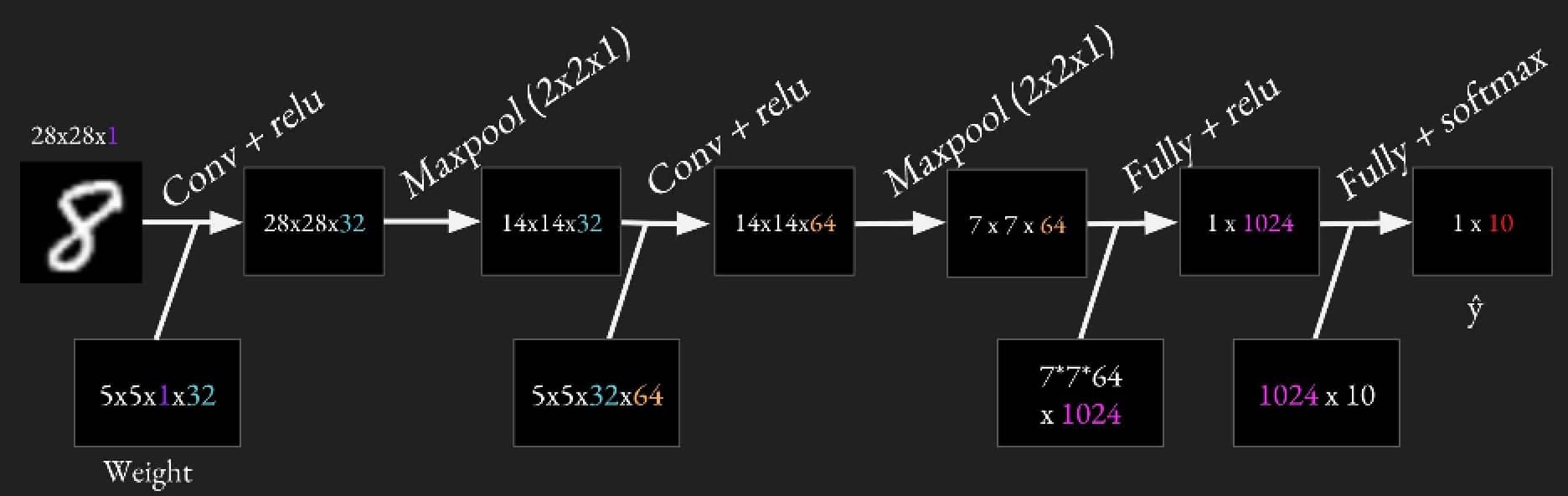
这里我们有两个卷积层,两个全连接层,两个池化层,所以我们要注意复用代码,具体请参考代码中的写法,用好 variable scope。
Convolutional Layer
对于卷积层,我们使用 tf.nn.conv2d 来构建,一般来说会把卷积层和 relu 合并到一起,函数大概长这样:
1 | def conv_relu(inputs, filters, k_size, stride, padding, scope_name): |
我们不需要去手动计算输出的维度,但是大概知道输入是如何变换的可以方便我们去调优,我们可以通过下面的公式来计算维度,其中:
- 输入图片的尺寸 W(对于 MNIST 来说是 28x28)
- 过滤器的尺寸 F(这里用 5x5)
- 步长 Stride S(这里用 1x1)
- Zero Padding 个数 P(这里是 2)
公式为 $ (W-F+2P)/S + 1 $,对应 MNIST 就是 (28 - 5 + 2*2)/1 + 1 = 28。关于 stride 如何影响尺寸的,可以参考 这里
Pooling
池化是一种用来降低维度的下采样技术,这里我们采用最常用的 MaxPooling 方法(关于 MaxPooling 可以参考上一讲的内容)。在 Tensorflow 中,我们可以使用 tf.nn.max_pool 来实现,具体为:
1 | def maxpool(inputs, ksize, stride, padding='VALID', scope_name='pool'): |
同样,我们给出 MaxPooling 输出的计算公式,其中:
- 输入图片的尺寸 W(对于 MNIST 来说是 28x28)
- 池化大小 K(这里用 2x2)
- 步长 Stride S(这里用 2x2)
- Zero Padding 个数 P(这里是 0)
公式为 $ (W-K+2P)/S + 1 $,对应 MNIST 就是 (28 - 2 + 2*0)/2 + 1 = 14。
Fully Connected
最后我们来看看全连接层,和我们之前实现的类似,具体如下:
1 | def fully_connected(inputs, out_dim, scope_name='fc'): |
最终结果
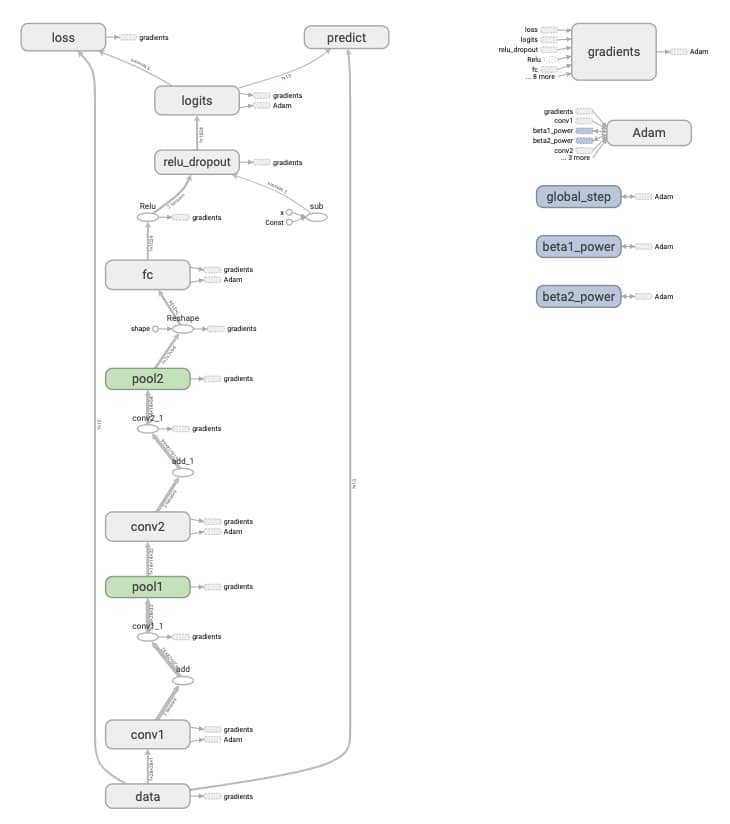
我们把前面的几层合到一起,训练一次之后打开 Tensorboard 看一下(命令 tensorboard --logdir='graphs/convnet/'),就可以看到非常整齐的模型结构!
准确率和 loss 的趋势为:
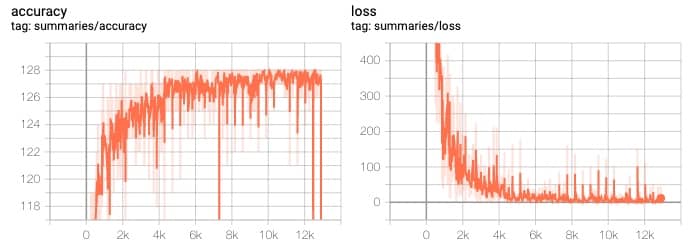
注:在我的机器上训练一轮大约需要 45s(没有 GPU)
其实….
其实,我们并不需要自己去写前面的各种层,因为 Tensorflow 提供了更加高阶的 tf.layers 接口,前面的几层代码可以这样写:
1 | # 卷积层 |
下期预告
- TFRecord
- CIFAR
- Style Transfer