上节课我们了解了如何通过 Word2Vec 来处理文本,这节课我们就来看看如何处理图像。
更新历史
- 2019.08.13: 完成初稿
计算机视觉
最常用的数据集是 ImageNet,包含 1000 个类别物体的 1431167 张图片。除了图片分类之外,比较常见的任务还有:物体检测,物体分割,姿态检测、自动为图片配文字、基于图片的问答、超分辨率、艺术画生成。
CNN
CNN 全称是 Convolutional Neural Networks。不过我们先从全连接神经网络讲起,一个简单的全连接矩阵计算如下图所示:

对于一个尺寸为 32x32x3 的图片来说,我们先要把这个图片摊平为 3072x1,然后用对应数量的神经元来进行计算:

而对于 CNN 来说,矩阵计算是这样的:
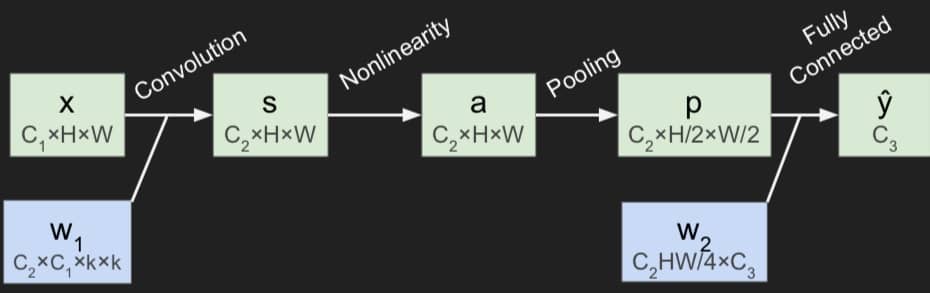
注意这里 H/W 为图片的高和宽,k 是卷积的矩阵长度,Pooling 是让 4 个像素合并为 1 个,才有上面的等式。针对某一个点的计算为
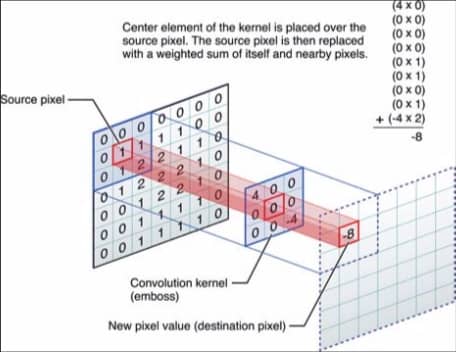
一个简单的例子
我们用一个简单的例子来说明下具体的计算过程,首先我们的图片长这样:
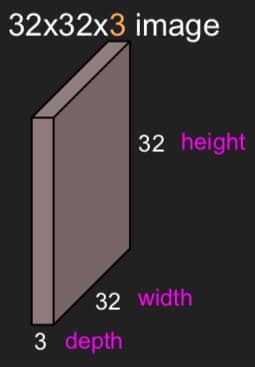
用来与图片做卷积的矩阵大小是 5x5x3(因为图片有 3 个通道),假设我们有 6 个这样 5x5x3 的矩阵(过滤器),最后就可以得到如下图所示的 activation maps
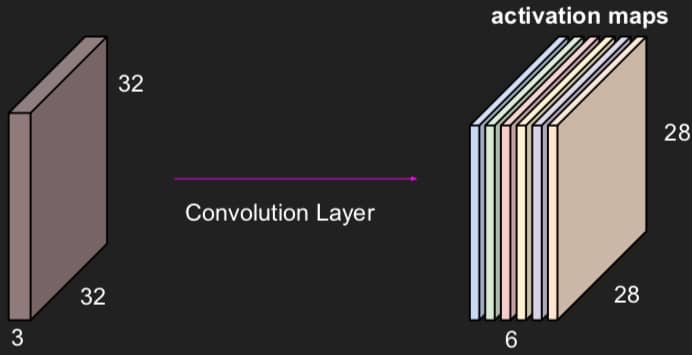
其中为啥是 6 个?因为我们有 6 个过滤器。为啥长和宽是 28?因为 32-5+1 = 28(这里是没有 padding 的情况,并且 stride 步长为 1)。完整的方程如下,其中 N 表示图像的宽度,F 表示过滤矩阵的宽度,这个方程的出来的结果必须是整数!
所谓的 ConvNet,就是把这样的操作多搞几次:
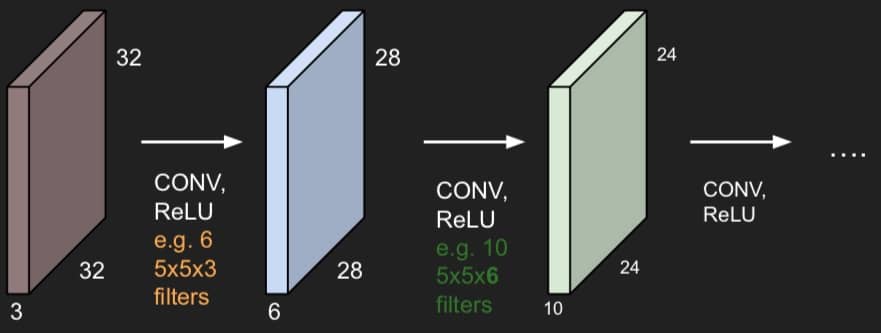
这种做法的两个关键启发:
- Features are hierarchical。从低复杂度的特征中组合出高复杂度的特征,比直接学习高复杂度的特征更加有效。比如我可以先学习识别直线、圆形之类的分类器,再训练一个组合圆形、直线这些基本图形的分类器
- Features are translationally invariant。可以保证特征的平移不变性(一定程度),可以提高模型的泛化效果。
在 TF 中,我们可以使用 tf.layers.conv2d 来构建 ConvNet,常用的参数组合(K 为过滤器数量,F 为过滤器的大小,S 为步长,P 为 zero padding)
- K = 2 的幂,如 32 64 128 512
- F = 3, S = 1, P = 1
- F = 5, S = 1, P = 2
- F = 5, S = 2, P = 满足 stride 的值
- F = 1, S = 1, P = 0
Pooling Layer
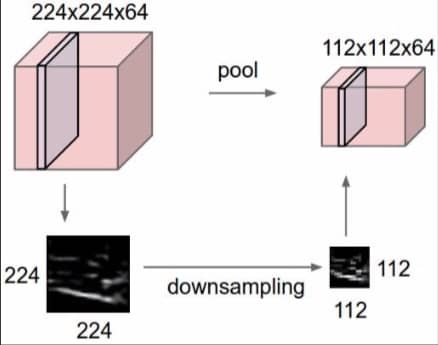
池化层的主要作用是缩小矩阵大小,减少计算量。注意,这里是针对每个 activation map 独立进行操作,如下图所示:
常用的是 Max Pooling,计算方式如下图所示,就是取最大的值:
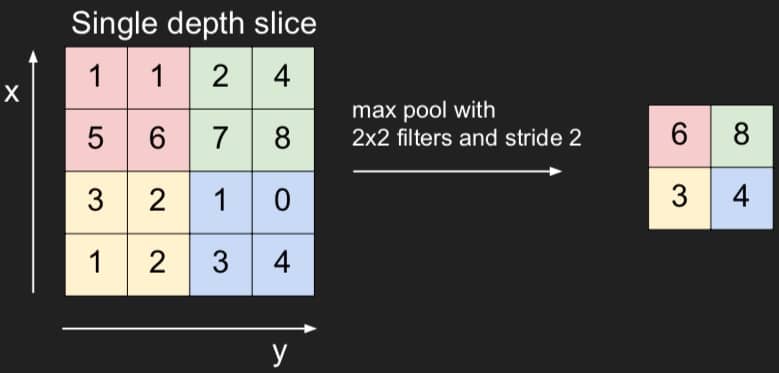
常用的参数组合(F 为过滤器的大小,S 为步长):
- F = 2, S = 2
- F = 3, S = 3
经典网络
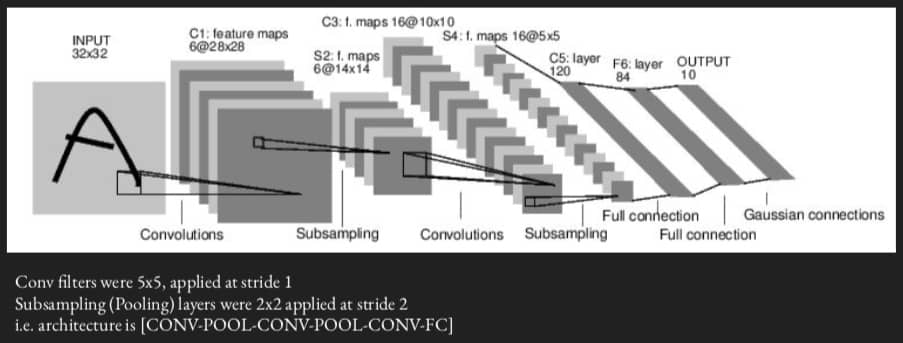
LeNet-5
AlexNet

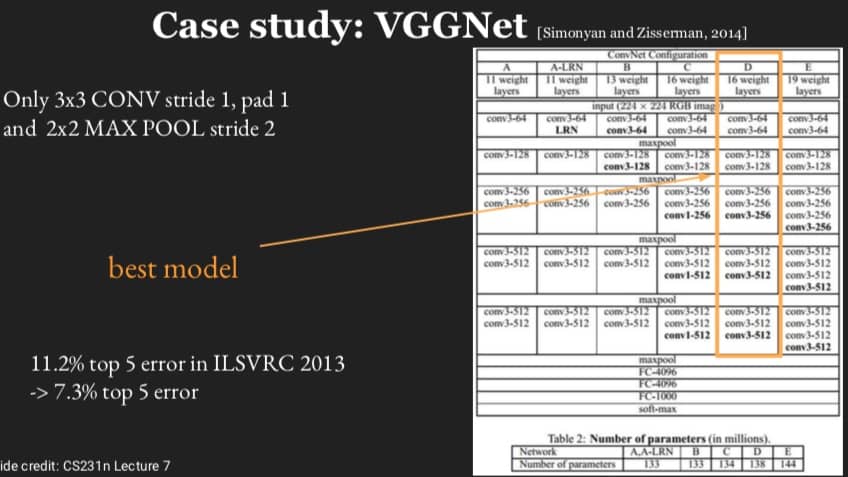
VGGNet
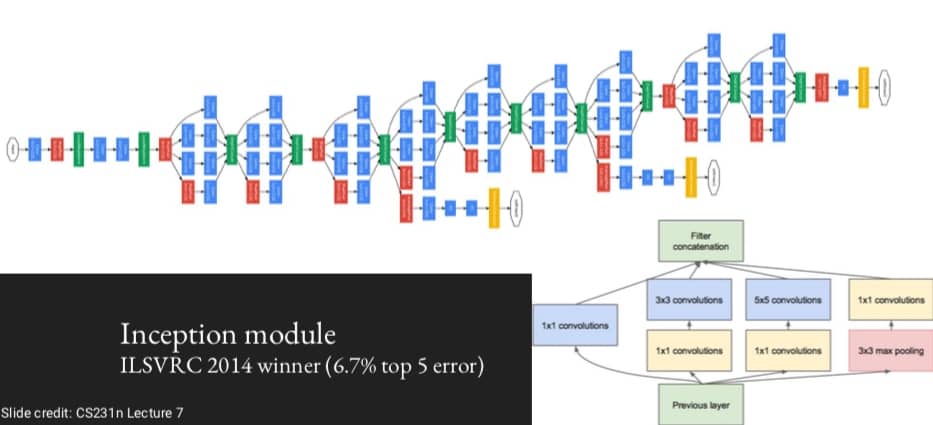
GoogLeNet
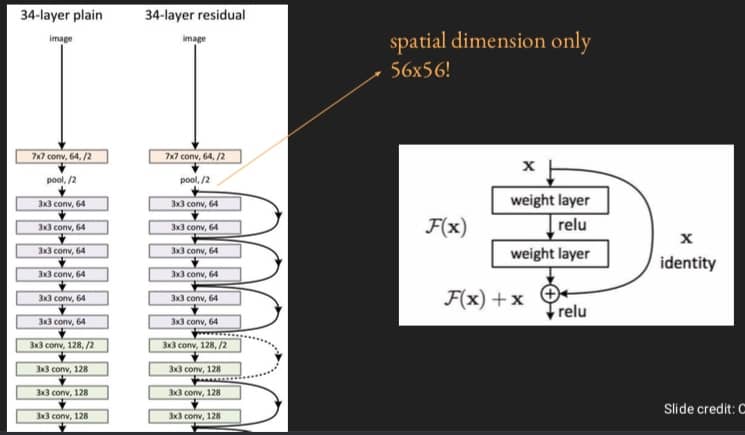
ResNet
下期预告
- ConvNet in TensorFlow