本文主要介绍了纵向联邦学习中用于可解释评分卡的机器学习算法及在信用评分中的应用,这里简单记录下核心的算法思路。
- 注 1:我个人的一些理解补充,主要放在文中的括号内,并会带有
注:
摘要
大数据和人工智能在风控领域有很多应用,如信用评分。在数据隐私保护越来越被重视的今天,我们针对传统评分卡提出了一种纵向联邦学习算法,算法基于 logistic regression with bounded contrains,命名为 FL-LRBC。最终得到的模型将只有正的系数,与此同时可以无需花费时间调整参数。FL-LRBC 算法在引入更多数据后可以有效增加 AUC 和 KS,并且已经应用在实际的商业场景中。(注:因为纵向联邦学习会引入新的特征,这个特征只要区分度够高,实际上肯定是会带来 AUC 和 KS 的大幅提升的,所以我们要关注其到底是如何划分数据和特征的。)
Introduction
论文里简单介绍了一下评分卡模型的用途,实际上就是通过分值的方式来区分出好和坏。评分卡模型一般都是基于 LR(因为可解释性和鲁棒性)。想要进一步提高准确性,一般有两种方法。第一种是引入更加复杂的模型,比如集成树模型和神经网络,但是因为可解释性不佳,实际很难应用在信贷中。第二种方法是引入更丰富的数据,这种方法一般来说就涉及到隐私数据的传输。
为了避免隐私数据传输,基于纵向联邦学习的算法是一个可行的解决方案。但是在实际场景中,为了得到比较好的模型,往往需要不断进行调参,使得模型系数大于等于 0 以保证可解释性和鲁棒性,这也使得模型的训练时间非常长。(注:这个其实要看具体数据量,信贷数据不会特别多,实际上论文中不得不放大这些问题,让论文看起来更出彩)
为了解决这些问题,我们基于 FATE 框架开发了带约束 LR,只需要一次训练过程就可以完成评分卡模型的训练,不需要反复进行调参。通过对银行数据+云闪付数据的实际测试,AUC 有 9% 的提升。
LR with Bounded Constraint in the Vertical FL Framework
这部分先介绍了基于 WOE 的 LR 评分卡模型,然后说明如何在纵向联邦框架上实现 FL-LRBC 算法。(注:关于评分卡不赘述,可以参考这里)
传统评分卡模型的流程图如下,这里注意各个系数都需要大于等于 0。传统方法中,通常采用 variance inflation factor(VIF) 或 correlation matrix 来保证系数非负:
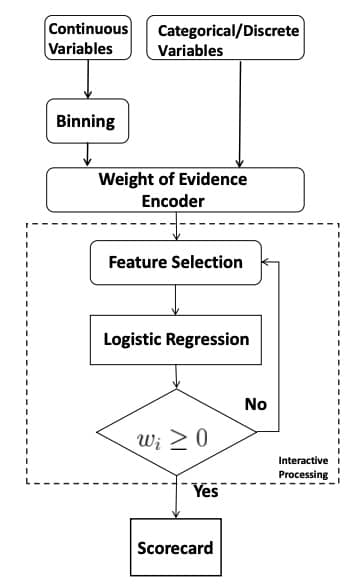
而在纵向联邦学习中,带约束的优化问题是不支持的,所以需要对原来的 LR 算法进行调整,问题定义如下图所示:
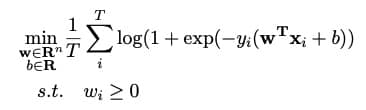
对于带条件约束的优化问题,可以通过 KKT 条件进行转化后进行运算,具体如下:

这里最重要的差别在于第六步中更新系数的方式,和传统的 SGD 是不一样的。
Experimental Results
总共有 400w 数据,其中 46w+ 正样本,最终有 14 个变量(guest 9 个,host 5 个)。具体的试验结果就不展开说了,毕竟论文肯定是要有提升的。这里的关键就是保证了除了 intercept 之外的系数都为正。
这里会出现一个问题,就是 woe 值的转化实际上只能在 guest 方进行,host 方只能用原始值(FATE 目前的设定)。从实验结果推断,guest 方进行了 woe 值替换,host 方没有进行处理。
Conclusion
最终的结论当然是快且有效,但具体落地的有效性和 host 方的数据质量直接相关,还需要进一步测试。