本文主要介绍了这篇历史悠久的领域自适应领域非常著名的文章,只需要对数据集做简单的调整,就可以达到不错的迁移学习的效果。
- 注 1:我个人的一些理解补充,主要放在文中的括号内,并会带有
注: - 注 2:论文内容比较零散,不会按照固定的框架写
首先要简单介绍一下领域自适应(Domain Adaptation),简单来说就是一个算法可以轻松从一个领域迁移到另一个领域。比如我现在有两组文本材料,一组是关于经济的,一组是关于计算机的。关于经济的文本很多,关于计算机的文本很少。直接用计算机文本训练出来的 NLP 模型效果较差(比如词性标注),那么有没有可能利用经济的文本来辅助提高计算机文本模型的效果呢?这就是领域自适应的问题。
领域自适应一般有两种方法,一种是监督学习,一种是半监督学习,论文主要介绍的是监督学习。相关工作这里有必要介绍一下,还是用前面的例子,一个词性标注任务,经济类文本数据集为 A,计算机类文本数据集为 B,且 A 的数据量远大于 B:
- SRCONLY 方法,只用 A 训练模型
- TGTONLY 方法,只用 B 训练模型
- ALL 方法,用 A+B 训练模型
- WEIGHTED 方法,因为 A 比 B 多太多,所以降低 A 的权重尽量保持平衡
- PRED 方法,先用 A 训练模型,然后用模型预测 B 得到一系列预测值 C,再用 B+C 训练模型
- LININT 方法,对 SRCONLY 和 TGTONLY 方法训练出来的模型的预测值做线性组合
以上主要用于 baseline,但其实并不容易超过,在论文发表的时候(2009)只有 2 种方法可以超过,分别是:
- PRIOR 方法,用 SRCONLY 方法训练出模型权重 w1,然后用 TGTONLY 方式训练模型,唯一的差别在于损失函数需要加入 w1,可以理解为在 TGTONLY 会尽量接近 SRCONLY 的权重
- 训练 3 个模型,分别针对 A,B 和 A+B,这种方法效果不错,但是耗时很长(后面基本没有再提过,但借鉴了这个思路)
说了这么多,其实方法很简单,就是把 A 和 B 的数据做一个预处理就可以,A 的数据处理为
一些对比如下,可以看到 AUGMENT 方法(也就是论文中的方法)在很多任务上都有提升,作者对此的解释是因为扩充了数据后模型会同时学到两类数据的信息(而不是像 PRIOR 方法一样是依次学习)
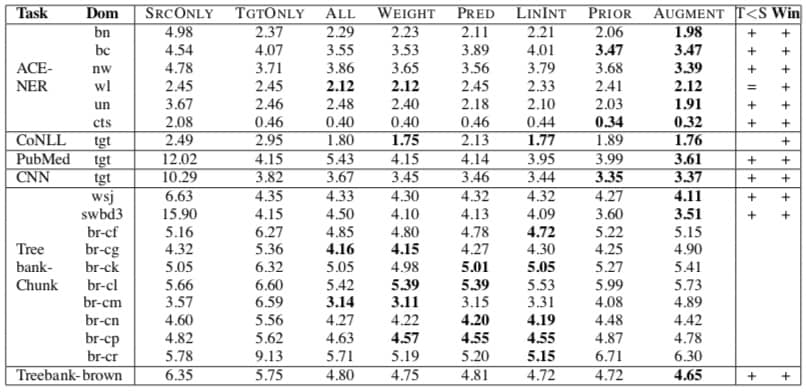
但是不幸的是,我们小组尝试了这个方法后,发现对实际模型效果并没有提升(甚至更差了),只能说可能刚好不适用吧。