FATE 作为目前最受欢迎的联邦学习开源项目,直接从源码来进行学习是非常好的途径。本文将从代码的角度来介绍 FATE 中的调度器 FATE Flow 的工作原理。
注:本文基于 FATE 1.5.0 版本,后续版本的代码将另外标注出变化。
分析与总结
因为文章太长,所以写在前面(笑)
不出意外的话,这篇文章截止发布时应该是全网最详尽的 FATE Flow 介绍和源码解析的文章。因为之前也自己实现过基于 DAG 的分布式调度器,所以看到很多当年的设计出现在 FATE 这样一个广受欢迎的开源框架中,感觉还是挺自豪的。当然了,也发现了不少可以优化和改进的地方,比如可以支持单步执行、执行到某个节点等更丰富的执行模式;比如可以更加优化代码的组织逻辑,而不是像现在这样纸包鸡包纸包鸡;比如可以采用更加统一的错误码及报错说明便于调试和排查错误;比如可以增加更丰富的调度器配置兼容不同的使用场景;诸如此类,不一而足。
不过话说回来,Talk is Cheap, Show Me The Code。FATE 能在这么短的时间内拿出这么大工程量的项目,且完成度很高,真的说明微众我的前同事们工作真的非常辛苦且卓有成效。道路是曲折的,前途是光明的。
后面我还会继续写一下联邦学习算法是如何被调度执行的(这部分在本文中非常简略),希望能对大家有所帮助。
FATE 总体架构
本文主要介绍 FATE Flow 的核心流程代码,作为核心调度器模块,会和系统中其他各个组件有较多交互,所以我们先来简单介绍一下整体的系统架构,方便后面说明和理解。

具体各个模块的说明如下:
- FATE Flow: 联邦学习的任务流水线管理模块(通俗理解就是调度器)
- FederatedML: 联邦机器学习的 Python 实现包(类比 scikit-learn)
- Cluster Manager: 集群管理器
- Node Manager: 节点管理器,管理每台机器的计算资源
- RollSite: 跨 Party 通讯组件,以前的版本里叫 Proxy+Federation
- Mysql: 数据库,FATE Flow 和 Cluster Manager 的数据在此存储
组件比较多,可以先有一个简单的了解,后面会跟随代码介绍各个模块的在代码中的交互关系。
FATE Flow 架构
FATE Flow 在 1.5 版本中有了一定的优化和增强,这里我们循序渐进介绍一下,下图是较早版本的架构,但仍然有参考意义:
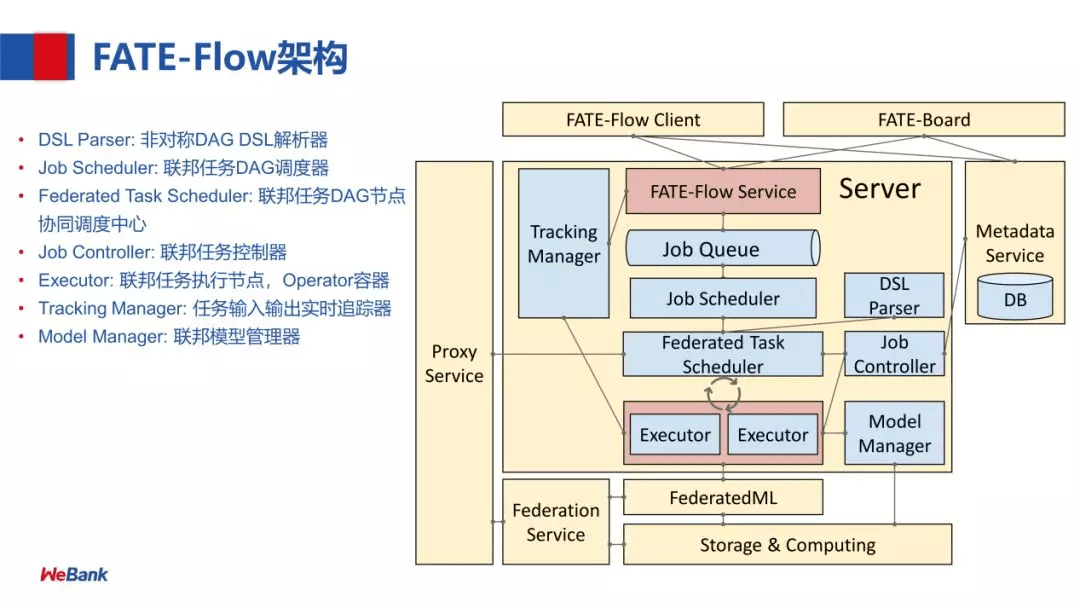
各个模块的功能如下(来自 构建端到端的联邦学习 Pipeline 生产服务):
- DSL Parser:是调度的核心,通过 DSL parser 解析到一个计算任务的上下游关系及依赖等。
- Job Scheduler:是 DAG 层面的调度,把 DAG 作为一个 Job,DAG 里面的节点执行称为 task,也就是说一个 Job 会包含若干个 task
- Federated Task Scheduler:最小调度粒度就是 task,需要调度多方运行同一个组件但参数算法不同的 task,结束后,继续调度下一个组件,这里就会涉及到协同调度
- Job Controller:联邦任务控制器
- Executor:联邦任务执行节点,支持不同的 Operator 容器,现在支持 Python 和 Script 的 Operator。Executor,在我们目前的应用中拉起 FederatedML 定义的一些组件,如 data io 数据输入输出,特征选择等模块,每次调起一个组件去执行,然后,这些组件会调用基础架构的 API,如 Storage 和 Federation Service (API 的抽象) ,再经过 Proxy 就可以和对端的 FATE-Flow 进行协同调度。
- 注:这里还用老版本的说明,即 Proxy+Federation,最新版本统一为 RollSite
- Tracking Manager:任务输入输出的实时追踪,包括每个 task 输出的 data 和 model。
- Model Manager:联邦模型管理器
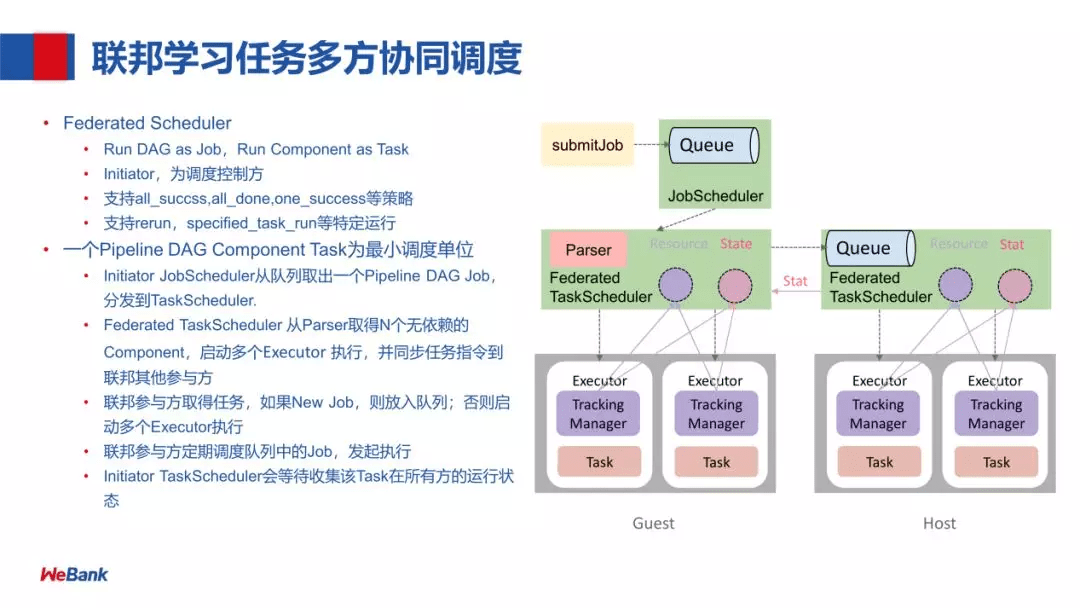
联邦学习任务多方协同调度的流程:
首先,是以任务提交的一种方式,提交任务到 Queue,然后 JobScheduler 会把这个任务拿出来给到 Federated TaskScheduler 调度,Federated TaskScheduler 通过 Parser 取得下游 N 个无依赖的 Component,再调度 Executor (由两部分组成:Tracking Manager 和 Task) 执行,同时这个任务会分发到联邦学习的各个参与方 Host。联邦参与方取得任务,如果是 New Job,则放入队列(参与方会定期调度队列中的 Job),否则启动多个 Executor 执行,Executor 在 run 的过程中,会利用 Federation API 进行联邦学习中的参数交互,对一个联邦学习任务,每一方的 Job id 是保持一致的,每跑一个 Component,它的 Task id 也是一致的。每个 Task 跑完 Initiator TaskScheduler 会收集各方的状态,进行下一步的调度。对于下一步的调度策略我们支持:all_succss,all_done,one_succss 等策略。由于基于 Task 为最小的调度单位,所以很容易实现 rerun,specified_task_run 等特定运行。
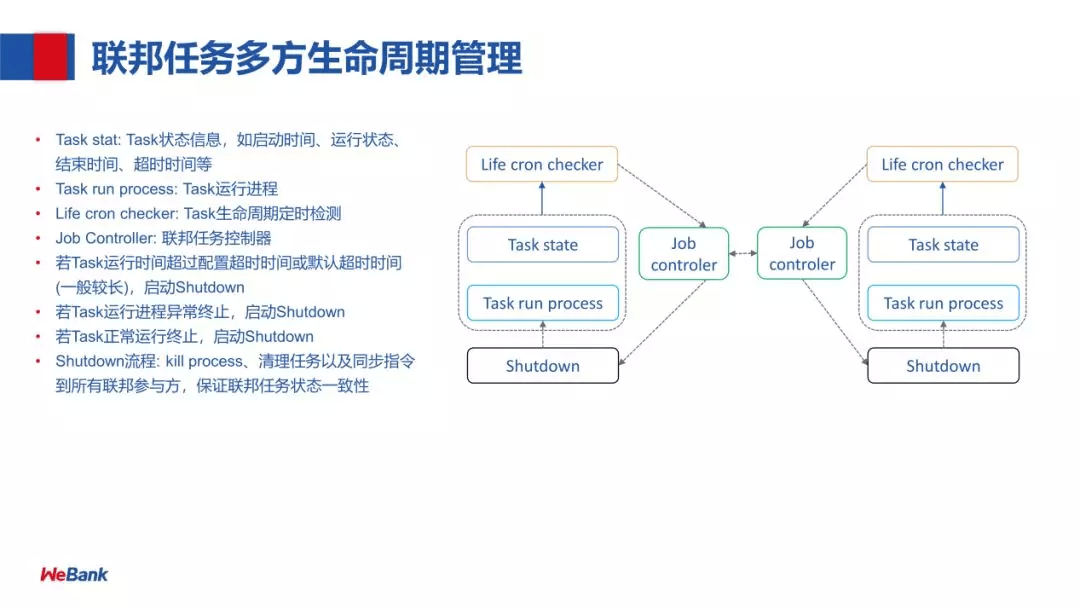
分以下几个部分:
- Task stat:Task 状态信息,如启动时间、运行状态、结束时间、超时时间等
- Task run process:Task 运行进程
- Life cron checker:Task 生命周期定时检测
- Job controller:联邦任务控制器
- Shutdown:kill process、清理任务以及同步指令到所有联邦参与方,保证联邦任务状态一致性
启动 Shutdown 的条件:
- 若 Task 运行时间超过配置超时时间或默认超时时间(一般较长),启动 Shutdown
- 若 Task 运行进程异常终止,启动 Shutdown
- 若 Task 正常运行终止,启动 Shutdown
最后,在 1.5.0 版本中的优化如下:

上面主要是基于官方的各类说明材料,比较抽象的架构图我们就介绍到这里,接下来我们就从代码入手,看看具体的实现吧。
源码框架流程
源码框架流程部分相对来说比较硬核和枯燥,我会尽量简化非必要的细节,点出关键要点,方便大家理解。首先,我们来看看代码的入口。
注:大部分相关代码均位于 python/fate_flow 文件夹中,少部分会位于 python/fate_arch 文件夹中。
FATE Flow Server
- 代码文件:
python/fate_flow/fate_flow_server.py
- 所用 Web 框架:Flask
熟悉 Flask 的朋友都知道,这是一个轻量级的 Python Web 框架,底层是基于 werkzeug,实际上也是通过 werkzeug 来提供并发支持的,具体启动的代码位于 113-121 行:
1
2
3
4
5
6
7
8
9
| try:
run_simple(hostname=IP, port=HTTP_PORT, application=app, threaded=True)
stat_logger.info("FATE Flow server start Successfully")
except OSError as e:
traceback.print_exc()
os.kill(os.getpid(), signal.SIGKILL)
except Exception as e:
traceback.print_exc()
os.kill(os.getpid(), signal.SIGKILL)
|
这里我们尤其要关注 run_simple 这个函数,这里采用 threaded=True 这个配置,说明 server 是以单进程多线程的方式启动,来处理并发的请求的。更多关于 werkzeug 的材料可以在文章最后的参考链接中找到,这里就不展开了。
接下来我们详细看看这个 Web Server 提供哪些功能,具体的功能都分散在不同的模块中,在 app 这个变量初始化是统一引入(这也是 Flask 的常用写法),具体代码位于 71-87 行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| app = DispatcherMiddleware(
manager,
{
'/{}/data'.format(API_VERSION): data_access_app_manager,
'/{}/model'.format(API_VERSION): model_app_manager,
'/{}/job'.format(API_VERSION): job_app_manager,
'/{}/table'.format(API_VERSION): table_app_manager,
'/{}/tracking'.format(API_VERSION): tracking_app_manager,
'/{}/pipeline'.format(API_VERSION): pipeline_app_manager,
'/{}/permission'.format(API_VERSION): permission_app_manager,
'/{}/version'.format(API_VERSION): version_app_manager,
'/{}/party'.format(API_VERSION): party_app_manager,
'/{}/initiator'.format(API_VERSION): initiator_app_manager,
'/{}/tracker'.format(API_VERSION): tracker_app_manager,
'/{}/forward'.format(API_VERSION): proxy_app_manager
}
)
|
这样的代码组织也使得我们只需要看对应不同 manager 的代码就能了解不同模块的功能,很好很合理。具体各个模块的功能如下(后面会分别详细说明):
- apps 文件夹
data_access_app_manager 提供数据集上传、下载、查询等功能job_app_manager【核心模块】提供 Job 和 Task 的提交、执行、查询、配置等功能model_app_manager 提供模型的载入、迁移、发布等功能,主要用于在线预测permission_app_manager 提供权限验证相关功能pipeline_app_manager 提供解析 DAG 各个组件依赖关系的功能proxy_app_manager 提供各 Party 间通信及调用功能table_app_manager 提供数据表的新增、删除等功能tracking_app_manager 提供 component 相关状态、数据等查询、下载功能version_app_manager 提供 FATE 相关版本查询功能
scheduler_apps 文件夹
initiator_app_manager 提供在角色为 initiator 的 Party 方进行 Job 重新执行、停止和更新状态等功能party_app_manager【核心模块】提供在各个 Party 执行 Job 相关动作的功能tracker_app_manager提供查询 component 执行状态、结果和输出数据等功能
这里大家可能有一点疑惑,这里的 job_app_manager 和 party_app_manager 提供的功能似乎是相似的,其实不一样,一个是对外的接口,一个是对内的接口,具体如下:
job_app_manager 提供的是对外使用的接口,可以被 flow client 或 http api 直接调用party_app_manager 提供的是对内使用的接口,主要被内部调度器调用
接下来就是各类配置和服务的初始化及后台启动,具体代码位于 98-111 行,这里直接通过注释来说明代码功能:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
RuntimeConfig.init_env()
RuntimeConfig.set_process_role(ProcessRole.DRIVER)
PrivilegeAuth.init()
ServiceUtils.register()
ResourceManager.initialize()
Detector(interval=5 * 1000).start()
DAGScheduler(interval=2 * 1000).start()
server = grpc.server(futures.ThreadPoolExecutor(max_workers=10),
options=[(cygrpc.ChannelArgKey.max_send_message_length, -1),
(cygrpc.ChannelArgKey.max_receive_message_length, -1)])
proxy_pb2_grpc.add_DataTransferServiceServicer_to_server(UnaryService(), server)
server.add_insecure_port("{}:{}".format(IP, GRPC_PORT))
server.start()
|
这里我们需要解开最后一个疑惑,为什么要另外启动一个 GRPC server?简单来说,FATE 会通过这个 GRPC Server 完成各个 Party 之间的函数调用,也就是说所有的 http 接口都通过本地调用,不同 Party 间的函数调用统一通过 grpc 的方式进行,而这个 grpc 的调用逻辑也很简单,实际上是通过解析 grpc 请求中的参数,对应再次调用上述 http 接口(主要是 party_app_manager)中的接口。关于 GRPC Server 的具体说明会在 文件夹 utils 一章详细介绍,这里只需要有粗略了解即可。
为了更便于大家理解具体的执行流程,接下来一节会以一个 Job 从提交到完成执行来进行说明各个模块的执行顺序和逻辑,因为步骤比较多,所以更具体的源码分析请参考后面 源码分析 章节。
Job 的生命周期
通过了解一个 Job 从提交到完成执行的各个步骤,基本可以掌握 FATE Flow 的关键所在,就像一条中轴线,其他的所有模块都是配合这条线而存在的。废话不多说,我们直接开始:
- 【任务提交】无论是通过 flow client 还是 http api 提交任务,实际上执行的都是
apps/job_app.py 中第 45 行的 submit_job 函数,在检查完 job 运行配置后,调用 DAGScheduler.submit() 完成任务提交(具体逻辑参考后文 dag_scheduler.py 的说明。具体执行的任务简单来说就是:生成 JobID -> 通知各 Party 创建 Job -> 各方均创建成功后,任务提交成功。提交成功后将由 DAGSchudler 进行调度执行,具体的调度逻辑在下一节会详细说明,这里主要围绕 Job 本身的流程进行介绍。
- 【等待 Job 调度】创建完成之后,Job 的状态为 waiting,在
DAGScheduler.run_do 函数中会从数据库中找到状态为 waiting 的任务,并通过 DAGScheduler.schedule_waiting_jobs 函数进行调度
- 【尝试启动 Job】若该 Job 开始被调度,则首先会向各 Party 通过
FederatedScheduler.resource_for_job 函数进行计算资源申请,若申请成功则通过 DAGScheduler.start_job 函数启动 Job;若某方没有足够的计算资源(注意:这个和申请失败不一样),则已经申请的资源需要退回;若资源申请失败,则通过 DAGScheduler.stop_job 函数停止 Job。如果 start_job 成功完成,Job 的状态将变为 running
- 【等待 Task 调度】Job 状态变为 running 之后,就会被
DAGScheduler.schedule_running_jobs 函数进行调度,实际调用的是 TaskScheduler.schedule 函数
- 【尝试调度 Task】若该 Task 开始被调度,则会通过
FederatedScheduler.start_task 函数在各方启动该 Task,实际上就是发起 grpc 调用,主要被调用的就是 party_app_manager 所提供的内部接口
- 【尝试启动 Task】被上一步 grpc 调用的接口是
party_app.py 中的 start_task 函数,实际执行的是 TaskController.start_task 函数,在底层是 EGGROLL 的情况下,就是通过 shell 执行对应的 python 脚本(通过 job_utils.run_subprocess 函数执行)
- 【执行 Task】具体 Task 的执行是通过
TaskExecutor.run_task 函数进行的,在这里我们将解析 job 和 task 的上下文和配置,并通过 run_object.run 函数进行执行。在这里因为是另外一个进程,所以是同步执行的,等 Task 执行完成后,会保存 data 和 model 并更新 Task 状态,便于调度器继续执行。注:具体任务的执行就不在这里展开讲了,后面会结合算法的开发另写一篇。
- 【完成 Job】每次进行 task 调度时,都会通过
DAGScheduler.calculate_job_status 函数来确定 Job 的状态,如果全部 Task 都 Success,那么 Job 的状态也变为 Success。至此,Job 执行完成。
注:这里因为篇幅关系,省略了部分细节,如状态更新、任务取消等,感兴趣的同学可以自行研究。
源码分析
这部分是具体各个文件的代码逻辑,建议配合上面 Job 的生命周期 阅读,当做细节查看手册,方便理解。
重点需要关注 federated_scheduler.py,只要理解了如何在多方同步调度,那么其他部分应该都可以迎刃而解了。
文件夹 controller
文件 job_controller.py
启动 Job start_job()
源码与逻辑说明如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
@classmethod
def JobController.start_job(cls, job_id, role, party_id, extra_info=None):
schedule_logger(job_id=job_id).info(f"try to start job {job_id} on {role} {party_id}")
job_info = {
"job_id": job_id,
"role": role,
"party_id": party_id,
"status": JobStatus.RUNNING,
"start_time": current_timestamp()
}
if extra_info:
schedule_logger(job_id=job_id).info(f"extra info: {extra_info}")
job_info.update(extra_info)
cls.update_job_status(job_info=job_info)
cls.update_job(job_info=job_info)
schedule_logger(job_id=job_id).info(f"start job {job_id} on {role} {party_id} successfully")
|
更新 Job 状态 update_job_status()
源码与逻辑说明如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
@classmethod
def update_job_status(cls, job_info):
update_status = JobSaver.update_job_status(job_info=job_info)
if update_status and EndStatus.contains(job_info.get("status")):
ResourceManager.return_job_resource(job_id=job_info["job_id"], role=job_info["role"], party_id=job_info["party_id"])
return update_status
@manager.route('/<job_id>/<role>/<party_id>/status/<status>', methods=['POST'])
def job_status(job_id, role, party_id, status):
job_info = {}
job_info.update({
"job_id": job_id,
"role": role,
"party_id": party_id,
"status": status
})
if JobController.update_job_status(job_info=job_info):
return get_json_result(retcode=0, retmsg='success')
else:
return get_json_result(retcode=RetCode.OPERATING_ERROR, retmsg="update job status failed")
|
文件 task_controller.py
启动 Task start_task()
源码与逻辑说明如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
| def start_task(cls, job_id, component_name, task_id, task_version, role, party_id):
"""
Start task, update status and party status
:param job_id:
:param component_name:
:param task_id:
:param task_version:
:param role:
:param party_id:
:return:
"""
schedule_logger(job_id).info(
'try to start job {} task {} {} on {} {} executor subprocess'.format(job_id, task_id, task_version, role, party_id))
task_executor_process_start_status = False
task_info = {
"job_id": job_id,
"task_id": task_id,
"task_version": task_version,
"role": role,
"party_id": party_id,
}
try:
task_dir = os.path.join(job_utils.get_job_directory(job_id=job_id), role, party_id, component_name, task_id, task_version)
os.makedirs(task_dir, exist_ok=True)
task_parameters_path = os.path.join(task_dir, 'task_parameters.json')
run_parameters_dict = job_utils.get_job_parameters(job_id, role, party_id)
with open(task_parameters_path, 'w') as fw:
fw.write(json_dumps(run_parameters_dict))
run_parameters = RunParameters(**run_parameters_dict)
schedule_logger(job_id=job_id).info(f"use computing engine {run_parameters.computing_engine}")
if run_parameters.computing_engine in {ComputingEngine.EGGROLL, ComputingEngine.STANDALONE}:
process_cmd = [
sys.executable,
sys.modules[TaskExecutor.__module__].__file__,
'-j', job_id,
'-n', component_name,
'-t', task_id,
'-v', task_version,
'-r', role,
'-p', party_id,
'-c', task_parameters_path,
'--run_ip', RuntimeConfig.JOB_SERVER_HOST,
'--job_server', '{}:{}'.format(RuntimeConfig.JOB_SERVER_HOST, RuntimeConfig.HTTP_PORT),
]
elif run_parameters.computing_engine == ComputingEngine.SPARK:
if "SPARK_HOME" not in os.environ:
raise EnvironmentError("SPARK_HOME not found")
spark_home = os.environ["SPARK_HOME"]
spark_submit_config = run_parameters.spark_run
deploy_mode = spark_submit_config.get("deploy-mode", "client")
if deploy_mode not in ["client"]:
raise ValueError(f"deploy mode {deploy_mode} not supported")
spark_submit_cmd = os.path.join(spark_home, "bin/spark-submit")
process_cmd = [spark_submit_cmd, f'--name={task_id}#{role}']
for k, v in spark_submit_config.items():
if k != "conf":
process_cmd.append(f'--{k}={v}')
if "conf" in spark_submit_config:
for ck, cv in spark_submit_config["conf"].items():
process_cmd.append(f'--conf')
process_cmd.append(f'{ck}={cv}')
process_cmd.extend([
sys.modules[TaskExecutor.__module__].__file__,
'-j', job_id,
'-n', component_name,
'-t', task_id,
'-v', task_version,
'-r', role,
'-p', party_id,
'-c', task_parameters_path,
'--run_ip', RuntimeConfig.JOB_SERVER_HOST,
'--job_server', '{}:{}'.format(RuntimeConfig.JOB_SERVER_HOST, RuntimeConfig.HTTP_PORT),
])
else:
raise ValueError(f"${run_parameters.computing_engine} is not supported")
task_log_dir = os.path.join(job_utils.get_job_log_directory(job_id=job_id), role, party_id, component_name)
schedule_logger(job_id).info(
'job {} task {} {} on {} {} executor subprocess is ready'.format(job_id, task_id, task_version, role, party_id))
p = job_utils.run_subprocess(job_id=job_id, config_dir=task_dir, process_cmd=process_cmd, log_dir=task_log_dir)
if p:
task_info["party_status"] = TaskStatus.RUNNING
task_info["start_time"] = current_timestamp()
task_executor_process_start_status = True
else:
task_info["party_status"] = TaskStatus.FAILED
except Exception as e:
schedule_logger(job_id).exception(e)
task_info["party_status"] = TaskStatus.FAILED
finally:
try:
cls.update_task(task_info=task_info)
cls.update_task_status(task_info=task_info)
except Exception as e:
schedule_logger(job_id).exception(e)
schedule_logger(job_id).info(
'job {} task {} {} on {} {} executor subprocess start {}'.format(job_id, task_id, task_version, role, party_id, "success" if task_executor_process_start_status else "failed"))
|
这里我们可以看到实际上任务的执行就是进行命令行调用,分为 EGGROLL 和 SPARK 两个不同的执行环境。
更新 task 状态 update_task_status()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| @classmethod
def update_task_status(cls, task_info):
update_status = JobSaver.update_task_status(task_info=task_info)
if update_status and EndStatus.contains(task_info.get("status")):
ResourceManager.return_task_resource(task_info=task_info)
cls.clean_task(job_id=task_info["job_id"],
task_id=task_info["task_id"],
task_version=task_info["task_version"],
role=task_info["role"],
party_id=task_info["party_id"],
content_type="table"
)
cls.report_task_to_initiator(task_info=task_info)
return update_status
@manager.route('/<job_id>/<component_name>/<task_id>/<task_version>/<role>/<party_id>/status/<status>', methods=['POST'])
def task_status(job_id, component_name, task_id, task_version, role, party_id, status):
task_info = {}
task_info.update({
"job_id": job_id,
"task_id": task_id,
"task_version": task_version,
"role": role,
"party_id": party_id,
"status": status
})
if TaskController.update_task_status(task_info=task_info):
return get_json_result(retcode=0, retmsg='success')
else:
return get_json_result(retcode=RetCode.OPERATING_ERROR, retmsg="update task status failed")
@classmethod
def report_task_to_initiator(cls, task_info):
tasks = JobSaver.query_task(task_id=task_info["task_id"],
task_version=task_info["task_version"],
role=task_info["role"],
party_id=task_info["party_id"])
if tasks[0].f_federated_status_collect_type == FederatedCommunicationType.PUSH:
FederatedScheduler.report_task_to_initiator(task=tasks[0])
|
文件夹 scheduler
文件 dag_scheduler.py
任务提交 submit()
源码与逻辑说明如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| def submit(cls, job_data, job_id=None):
if not job_id:
job_id = job_utils.generate_job_id()
job = Job()
job.f_job_id = job_id
job.f_initiator_role = job_initiator['role']
job.f_initiator_party_id = job_initiator['party_id']
JobController.initialize_tasks(job_id, role, party_id, False, job.f_initiator_role, job.f_initiator_party_id, common_job_parameters, dsl_parser)
status_code, response = FederatedScheduler.create_job(job=job)
if status_code != FederatedSchedulingStatusCode.SUCCESS:
job.f_status = JobStatus.FAILED
job.f_tag = "submit_failed"
FederatedScheduler.sync_job_status(job=job)
raise Exception("create job failed", response)
|
上面这段代码中有三个关键函数,具体说明如下:
JobController.initialize_tasks -> TaskController.create_task -> JobSaver.create_task 这部分都是在 initiator 的数据库中创建记录,用 peewee 操作(peewee 是一个 python 的 orm 库),这一步基本不会出错,也就是说先创建了对应 taskFederatedScheduler.create_job -> self.job_command(command='create') -> api_utils.federated_api -> api_utils.remote_api(重试次数为 3)这一步会读取 roles 里的各个角色,通过 grpc 调用进行 Job 创建,需要全部都创建成功才是成功FederatedScheduler.sync_job_status -> self.job_command(command='status/failed')
-> api_utils.federated_api -> api_utils.remote_api(重试次数为 3)创建不成功才进行同步,一般创建不成功也是因为网络问题。
调度循环 run_do()
源码与逻辑说明如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
def run_do(self):
schedule_logger().info("start schedule waiting jobs")
jobs = JobSaver.query_job(is_initiator=True, status=JobStatus.WAITING, order_by="create_time", reverse=False)
schedule_logger().info(f"have {len(jobs)} waiting jobs")
if len(jobs):
job = jobs[0]
schedule_logger().info(f"schedule waiting job {job.f_job_id}")
try:
self.schedule_waiting_jobs(job=job)
except Exception as e:
schedule_logger(job.f_job_id).exception(e)
schedule_logger(job.f_job_id).error(f"schedule waiting job {job.f_job_id} failed")
schedule_logger().info("schedule waiting jobs finished")
|
调度 waiting 状态 Job schedule_waiting_jobs()
源码与逻辑说明如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
def schedule_waiting_jobs(cls, job):
if job.f_cancel_signal:
job.f_status = JobStatus.CANCELED
FederatedScheduler.sync_job_status(job=job)
schedule_logger(job_id).info(f"job {job_id} have cancel signal")
return
apply_status_code, federated_response = FederatedScheduler.resource_for_job(job=job, operation_type=ResourceOperation.APPLY)
if apply_status_code == FederatedSchedulingStatusCode.SUCCESS:
cls.start_job(job_id=job_id, initiator_role=initiator_role, initiator_party_id=initiator_party_id)
update_status = cls.ready_signal(job_id=job_id, set_or_reset=False)
schedule_logger(job_id).info(f"reset job {job_id} ready signal {update_status}")
|
调度 running 状态 Job scheduler_running_job()
源码与逻辑说明如下:
对于 waiting 的 Job,如果一切顺利,会进入 running 状态,具体 running Job 的逻辑如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
def schedule_running_job(cls, job):
dsl_parser = schedule_utils.get_job_dsl_parser(dsl=job.f_dsl,
runtime_conf=job.f_runtime_conf_on_party,
train_runtime_conf=job.f_train_runtime_conf)
task_scheduling_status_code, tasks = TaskScheduler.schedule(job=job, dsl_parser=dsl_parser, canceled=job.f_cancel_signal)
tasks_status = [task.f_status for task in tasks]
new_job_status = cls.calculate_job_status(task_scheduling_status_code=task_scheduling_status_code, tasks_status=tasks_status)
if new_job_status == JobStatus.WAITING and job.f_cancel_signal:
new_job_status = JobStatus.CANCELED
total, finished_count = cls.calculate_job_progress(tasks_status=tasks_status)
FederatedScheduler.sync_job(job=job, update_fields=["progress"])
cls.update_job_on_initiator(initiator_job=job, update_fields=["progress"])
FederatedScheduler.sync_job_status(job=job)
cls.update_job_on_initiator(initiator_job=job, update_fields=["status"])
|
这里我们需要关注的重点是 TaskScheduler.schedule(job=job, dsl_parser=dsl_parser, canceled=job.f_cancel_signal),实际在这里进行 Task 的执行
启动 Job start_job()
源码与逻辑说明如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| def start_job(cls, job_id, initiator_role, initiator_party_id):
job_info = {}
job_info["job_id"] = job_id
job_info["role"] = initiator_role
job_info["party_id"] = initiator_party_id
job_info["status"] = JobStatus.RUNNING
job_info["party_status"] = JobStatus.RUNNING
job_info["start_time"] = current_timestamp()
job_info["tag"] = 'end_waiting'
jobs = JobSaver.query_job(job_id=job_id, role=initiator_role, party_id=initiator_party_id)
if jobs:
job = jobs[0]
FederatedScheduler.start_job(job=job)
schedule_logger(job_id=job_id).info("start job {} on initiator {} {}".format(job_id, initiator_role, initiator_party_id))
else:
schedule_logger(job_id=job_id).error("can not found job {} on initiator {} {}".format(job_id, initiator_role, initiator_party_id))
|
从上面我们可以看到关键在于 FederatedScheduler.start_job,实际执行的函数是 job_command(command='start'),这里的调用在 guest 和 host 都会执行。继续看 job_command 函数的源码,就会发现具体的执行是通过 api_utils.remote_api,实际执行的是 JobController.start_job
文件 task_scheduler.py
调度 Task schedule()
源码与逻辑说明如下:
1
2
3
4
5
6
7
8
9
10
11
|
class TaskScheduler(object):
@classmethod
def schedule(cls, job, dsl_parser, canceled=False):
if len(tasks_status_on_all) > 1 or TaskStatus.RUNNING in tasks_status_on_all:
cls.collect_task_of_all_party(job=job, task=initiator_task)
FederatedScheduler.sync_task_status(job=job, task=initiator_task)
status_code = cls.start_task(job=job, task=waiting_task)
|
启动 Task start_task()
源码与逻辑说明如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| def start_task(cls, job, task):
apply_status = ResourceManager.apply_for_task_resource(
task_info=task.to_human_model_dict(only_primary_with=["status"]))
task.f_status = TaskStatus.RUNNING
update_status = JobSaver.update_task_status(
task_info=task.to_human_model_dict(only_primary_with=["status"]))
FederatedScheduler.sync_task_status(job=job, task=task)
task_parameters = {}
status_code, response = FederatedScheduler.start_task(job=job, task=task,
task_parameters=task_parameters)
|
注意,这里的代码其实是有一点问题的,如果仔细看过执行日志就会发现经常出现 update status failed 这个问题,好在这个问题其实并不影响任务继续执行,具体出问题的原因是:
在 JobSaver.update_task_status 时,该 task 的状态已经变成 running,而后面的 FederatedScheduler.sync_task_status 会再次在 guest 上尝试更新状态,而其中的过滤条件有一个是 status = waiting,所以就会导致无法正常更新(因为已经不是 waiting 状态了),但不影响结果。其他的结果类似,都是因为已经更新过,导致再次更新出现问题。
文件 federated_scheduler.py
启动 Task start_task()
源码与逻辑说明如下:
1
2
| def start_task(cls, job, task, task_parameters):
return cls.task_command(job=job, task=task, command="start", command_body=task_parameters)
|
我们可以看到实际是调用 task_command() 执行,具体见下一小节
通用 Task 指令 task_command()
源码与逻辑说明如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| def task_command(cls, job, task, command, command_body=None):
federated_response = {}
job_parameters = job.f_runtime_conf_on_party["job_parameters"]
dsl_parser = schedule_utils.get_job_dsl_parser(dsl=job.f_dsl, runtime_conf=job.f_runtime_conf_on_party, train_runtime_conf=job.f_train_runtime_conf)
component = dsl_parser.get_component_info(component_name=task.f_component_name)
component_parameters = component.get_role_parameters()
for dest_role, parameters_on_partys in component_parameters.items():
federated_response[dest_role] = {}
for parameters_on_party in parameters_on_partys:
dest_party_id = parameters_on_party.get('local', {}).get('party_id')
try:
response = federated_api(job_id=task.f_job_id,
method='POST',
endpoint='/party/{}/{}/{}/{}/{}/{}/{}'.format(
task.f_job_id,
task.f_component_name,
task.f_task_id,
task.f_task_version,
dest_role,
dest_party_id,
command
),
src_party_id=job.f_initiator_party_id,
dest_party_id=dest_party_id,
src_role=job.f_initiator_role,
json_body=command_body if command_body else {},
federated_mode=job_parameters["federated_mode"])
federated_response[dest_role][dest_party_id] = response
except Exception as e:
federated_response[dest_role][dest_party_id] = {
"retcode": RetCode.FEDERATED_ERROR,
"retmsg": "Federated schedule error, {}".format(str(e))
}
if federated_response[dest_role][dest_party_id]["retcode"]:
schedule_logger(job_id=job.f_job_id).warning("an error occurred while {} the task to role {} party {}: \n{}".format(
command,
dest_role,
dest_party_id,
federated_response[dest_role][dest_party_id]["retmsg"]
))
return cls.return_federated_response(federated_response=federated_response)
|
这里我们看到实际上是通过 api_utils.federated_api 函数来进行 task 的发起。
同步 task 状态 sync_task_status()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
@classmethod
def sync_task_status(cls, job, task):
schedule_logger(job_id=task.f_job_id).info(
"job {} task {} {} is {}, sync to all party".format(task.f_job_id,
task.f_task_id,
task.f_task_version,
task.f_status))
status_code, response = cls.task_command(job=job, task=task, command=f"status/{task.f_status}")
if status_code == FederatedSchedulingStatusCode.SUCCESS:
schedule_logger(job_id=task.f_job_id).info(
"sync job {} task {} {} status {} to all party success".format(task.f_job_id,
task.f_task_id,
task.f_task_version,
task.f_status))
else:
schedule_logger(job_id=task.f_job_id).info(
"sync job {} task {} {} status {} to all party failed: \n{}".format(task.f_job_id,
task.f_task_id,
task.f_task_version,
task.f_status,
response))
return status_code, response
endpoint='/party/{}/{}/{}/{}/{}/{}/{}'.format(
task.f_job_id,
task.f_component_name,
task.f_task_id,
task.f_task_version,
dest_role,
dest_party_id,
command
)
|
同步状态时很容易因为网络波动而失败导致任务卡住,这个是一个优化点。
文件夹 scheduler_apps
文件 party_app.py
这里只选择用于 grpc 调用的代码进行说明。
设置 task 状态 task_status()
源码与逻辑说明如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
@manager.route('/<job_id>/<component_name>/<task_id>/<task_version>/<role>/<party_id>/status/<status>', methods=['POST'])
def task_status(job_id, component_name, task_id, task_version, role, party_id, status):
task_info = {}
task_info.update({
"job_id": job_id,
"task_id": task_id,
"task_version": task_version,
"role": role,
"party_id": party_id,
"status": status
})
if TaskController.update_task_status(task_info=task_info):
return get_json_result(retcode=0, retmsg='success')
else:
return get_json_result(retcode=RetCode.OPERATING_ERROR, retmsg="update task status failed")
|
该文件中的接口均用于被 grpc server 调用
启动 Task start_task()
源码与逻辑说明如下:
1
2
3
4
5
| @manager.route('/<job_id>/<component_name>/<task_id>/<task_version>/<role>/<party_id>/start', methods=['POST'])
@request_authority_certification
def start_task(job_id, component_name, task_id, task_version, role, party_id):
TaskController.start_task(job_id, component_name, task_id, task_version, role, party_id)
return get_json_result(retcode=0, retmsg='success')
|
启动 Task 实际上就是调用 TaskController.start_task 函数,参考后面对应章节。
文件夹 operation
文件 job_saver.py
更新 task 状态 update_task_status()
源码与逻辑说明如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
def update_task_status(cls, task_info):
schedule_logger(job_id=task_info["job_id"]).info("try to update job {} task {} {} status".format(task_info["job_id"], task_info["task_id"], task_info["task_version"]))
update_status = cls.update_status(Task, task_info)
if update_status:
schedule_logger(job_id=task_info["job_id"]).info("update job {} task {} {} status successfully: {}".format(task_info["job_id"], task_info["task_id"], task_info["task_version"], task_info))
else:
schedule_logger(job_id=task_info["job_id"]).info("update job {} task {} {} status update does not take effect: {}".format(task_info["job_id"], task_info["task_id"], task_info["task_version"], task_info))
return update_status
'''
因为 update_status 为 false,所以日志中出现 does not take effect,
于是来看 cls.update_status() 函数,在 111 行,要更新的 task_info 如下
{
'job_id': '2021040705593695988511',
'task_id': '2021040705593695988511_secure_add_example_0',
'task_version': '0',
'role': 'guest',
'party_id': '10001',
'status': 'running'
}
函数如下
'''
@DB.connection_context()
def update_status(cls, entity_model, entity_info):
...
def execute_update(cls, old_obj, model, update_info, update_filters):
update_fields = {}
for k, v in update_info.items():
attr_name = 'f_%s' % k
if hasattr(model, attr_name) and attr_name not in model.get_primary_keys_name():
update_fields[operator.attrgetter(attr_name)(model)] = v
if update_fields:
if update_filters:
operate = old_obj.update(update_fields).where(*update_filters)
else:
operate = old_obj.update(update_fields)
sql_logger(job_id=update_info.get("job_id", "fate_flow")).info(operate)
return operate.execute() > 0
else:
return False
|
这部分是更新数据库的代码,只需要了解即可。
文件夹 utils
文件 grpc_utils.py
源码与逻辑说明如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
|
server = grpc.server(futures.ThreadPoolExecutor(max_workers=10),
options=[(cygrpc.ChannelArgKey.max_send_message_length, -1),
(cygrpc.ChannelArgKey.max_receive_message_length, -1)])
proxy_pb2_grpc.add_DataTransferServiceServicer_to_server(UnaryService(), server)
server.add_insecure_port("{}:{}".format(IP, GRPC_PORT))
server.start()
class UnaryService(proxy_pb2_grpc.DataTransferServiceServicer):
def unaryCall(self, _request, context):
packet = _request
header = packet.header
_suffix = packet.body.key
param_bytes = packet.body.value
param = bytes.decode(param_bytes)
job_id = header.task.taskId
src = header.src
dst = header.dst
method = header.operator
param_dict = json_loads(param)
param_dict['src_party_id'] = str(src.partyId)
source_routing_header = []
for key, value in context.invocation_metadata():
source_routing_header.append((key, value))
stat_logger.info(f"grpc request routing header: {source_routing_header}")
_routing_metadata = get_routing_metadata(src_party_id=src.partyId, dest_party_id=dst.partyId)
context.set_trailing_metadata(trailing_metadata=_routing_metadata)
try:
nodes_check(param_dict.get('src_party_id'), param_dict.get('_src_role'), param_dict.get('appKey'),
param_dict.get('appSecret'), str(dst.partyId))
except Exception as e:
resp_json = {
"retcode": 100,
"retmsg": str(e)
}
return wrap_grpc_packet(resp_json, method, _suffix, dst.partyId, src.partyId, job_id)
param = bytes.decode(bytes(json_dumps(param_dict), 'utf-8'))
action = getattr(requests, method.lower(), None)
audit_logger(job_id).info('rpc receive: {}'.format(packet))
if action:
audit_logger(job_id).info("rpc receive: {} {}".format(get_url(_suffix), param))
resp = action(url=get_url(_suffix), data=param, headers=HEADERS)
else:
pass
resp_json = resp.json()
return wrap_grpc_packet(resp_json, method, _suffix, dst.partyId, src.partyId, job_id)
action = getattr(requests, method.lower(), None)
resp = action(url=get_url(_suffix), data=param, headers=HEADERS)
'''
再配合一个 rpc call 的例子,就知道具体在调用什么了
1. _suffix 就是下面的 body.key,即 /v1/party/2021040705593695988511/secure_add_example_0
/2021040705593695988511_secure_add_example_0/0/guest/10001/status/running
2. param 就是下面的 body.value,即 "{\"src_role\": \"guest\"}"
3. headers 就是下面的 header 部分,记录了所有的信息
4. method 是 header.operator,下面那里就是 POST
5. 最终的调用实际上就是通过 requests 库发送请求,访问 HTTP PORT(通过 get_url 拼接) ,具体进行调用
'''
def get_url(_suffix):
return "http://{}:{}/{}".format(RuntimeConfig.JOB_SERVER_HOST,
RuntimeConfig.HTTP_PORT, _suffix.lstrip('/'))
'''
一个 GRPC 请求参考
[INFO] [2021-04-07 05:59:38,399] [9:140194871224064] - grpc_utils.py[line:108]: rpc receive: header {
task {
taskId: "2021040705593695988511"
}
src {
name: "2021040705593695988511"
partyId: "10001"
role: "fateflow"
callback {
ip: "192.167.0.100"
port: 9360
}
}
dst {
name: "2021040705593695988511"
partyId: "10001"
role: "fateflow"
}
command {
name: "fateflow"
}
operator: "POST"
conf {
overallTimeout: 120000
}
}
body {
key: "/v1/party/2021040705593695988511/secure_add_example_0/2021040705593695988511_secure_add_example_0/0/guest/10001/status/running"
value: "{\"src_role\": \"guest\"}"
}
'''
|
文件 api_utils.py
联邦 api 调用 federated_api()
源码与逻辑说明如下:
1
2
3
4
5
6
7
8
9
10
11
| def federated_api(job_id, method, endpoint, src_party_id, dest_party_id, src_role, json_body, federated_mode, api_version=API_VERSION,
overall_timeout=DEFAULT_GRPC_OVERALL_TIMEOUT):
if int(dest_party_id) == 0:
federated_mode = FederatedMode.SINGLE
if federated_mode == FederatedMode.SINGLE:
return local_api(job_id=job_id, method=method, endpoint=endpoint, json_body=json_body, api_version=api_version)
elif federated_mode == FederatedMode.MULTIPLE:
return remote_api(job_id=job_id, method=method, endpoint=endpoint, src_party_id=src_party_id, src_role=src_role,
dest_party_id=dest_party_id, json_body=json_body, api_version=api_version, overall_timeout=overall_timeout)
else:
raise Exception('{} work mode is not supported'.format(federated_mode))
|
因为我们主要采用多方的模式,所以主要执行的是 remote_api 函数
远程 api 调用 remote_api()
源码与逻辑说明如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| def remote_api(job_id, method, endpoint, src_party_id, dest_party_id, src_role, json_body, api_version=API_VERSION,
overall_timeout=DEFAULT_GRPC_OVERALL_TIMEOUT, try_times=3):
endpoint = f"/{api_version}{endpoint}"
json_body['src_role'] = src_role
if CHECK_NODES_IDENTITY:
get_node_identity(json_body, src_party_id)
_packet = wrap_grpc_packet(json_body, method, endpoint, src_party_id, dest_party_id, job_id,
overall_timeout=overall_timeout)
_routing_metadata = get_routing_metadata(src_party_id=src_party_id, dest_party_id=dest_party_id)
exception = None
for t in range(try_times):
try:
channel, stub = get_command_federation_channel()
_return, _call = stub.unaryCall.with_call(_packet, metadata=_routing_metadata, timeout=(overall_timeout/1000))
audit_logger(job_id).info("grpc api response: {}".format(_return))
channel.close()
response = json_loads(_return.body.value)
return response
except Exception as e:
exception = e
else:
tips = ''
if 'Error received from peer' in str(exception):
tips = 'Please check if the fate flow server of the other party is started. '
if 'failed to connect to all addresses' in str(exception):
tips = 'Please check whether the rollsite service(port: 9370) is started. '
raise Exception('{}rpc request error: {}'.format(tips, exception))
|
这里会通过 channel, stub = get_command_federation_channel() 获取到 stub 然后进行调用,也就是说,所有调用 federated_api 实际上就是发起 grpc 调用
文件 job_utils.py
执行 task 命令 run_subprocess()
源码与逻辑说明如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| def run_subprocess(job_id, config_dir, process_cmd, log_dir=None):
schedule_logger(job_id=job_id).info('start process command: {}'.format(' '.join(process_cmd)))
os.makedirs(config_dir, exist_ok=True)
if log_dir:
os.makedirs(log_dir, exist_ok=True)
std_log = open(os.path.join(log_dir if log_dir else config_dir, 'std.log'), 'w')
pid_path = os.path.join(config_dir, 'pid')
if os.name == 'nt':
startupinfo = subprocess.STARTUPINFO()
startupinfo.dwFlags |= subprocess.STARTF_USESHOWWINDOW
startupinfo.wShowWindow = subprocess.SW_HIDE
else:
startupinfo = None
p = subprocess.Popen(process_cmd,
stdout=std_log,
stderr=std_log,
startupinfo=startupinfo
)
with open(pid_path, 'w') as f:
f.truncate()
f.write(str(p.pid) + "\n")
f.flush()
schedule_logger(job_id=job_id).info('start process command: {} successfully, pid is {}'.format(' '.join(process_cmd), p.pid))
return p
|
这里我们可以看到实际上就是通过拉起新的进程完成计算任务,并将对应的 pid 写入到文件中便于检查。
参考链接
FATE 相关
Werkzeug 相关