上节课我们使用 char-RNN 构造了一个可以模仿特朗普推特的语言模型,这节课我们来看看深度学习在自然语言处理领域的另一个重要应用 —— 机器翻译。
更新历史
- 2019.08.26: 完成初稿
机器翻译的进化
机器翻译就是机器来做翻译,这里涉及的神经网络架构是 sequence-to-sequence(也是该技术的主要应用场景),而如果想要提高效果,我们就离不开名为 attention 的神经网络技术。
1950s 基于规则
机器翻译在 1950 年代早期开始研究,主要是受冷战的影响,从俄文翻译为英文(可以参考 这里)。这些翻译系统基本上是基于规则的,通过语法词典把俄语词汇映射到对应的英语词汇。在这个过程中顺手发明了快排,surprise!
1990s-2010s 统计机器翻译 SMT
在 1990-2010 年代,机器翻译主要是基于统计学的,从数据中学习语言的概率模型。假设我们要把法语翻译成英语,那么我们的目标是找到最佳的英语语句 y,对于给定的法语语句 x,有如下关系:
然后再根据贝叶斯定理,把公式转化为两个部分,对这两个部分分别进行训练:
其中:
- $P(x|y)$ 是翻译模型,主要学习如何对句子进行翻译,从英文和法文问问中学习
- $P(y)$ 是语言模型,主要学习如何写出优秀的英文句子,从英文文本中学习
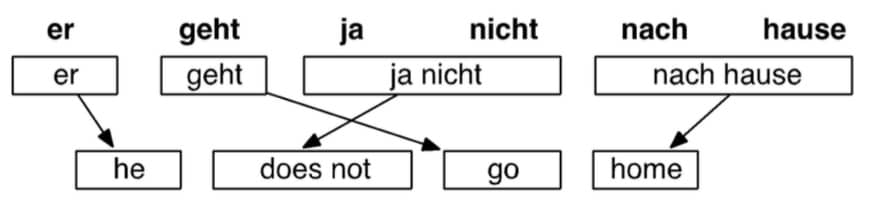
那么问题又来了,我们要如何学习 $P(x|y)$ 呢?首先我们需要大量的 parallel data(也就是人工翻译好的法语/英语一一对应的句子)。进一步分解公式,我们要求的是 $P(x, a|y)$,这里的 a 称为 alignment,表示词级别的对应关系(word-level correspondence between French sentence x and English sentence y)
这个概念可能有点抽象,我们可以简单理解为这个 alignment 就是寻找英语和法语句子中单词匹配的过程。
情况一:有的单词没有对应的词汇
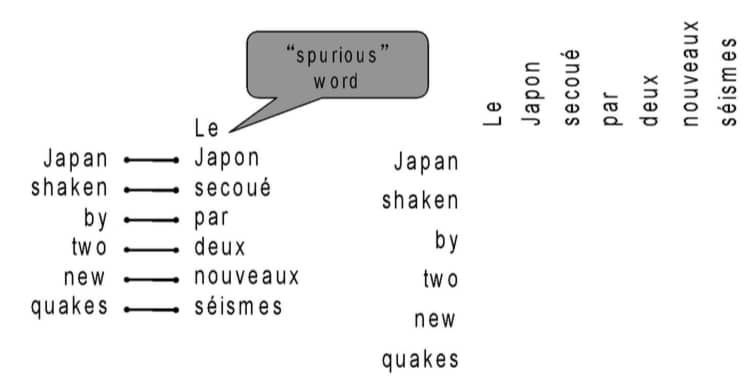
情况二:有的单词可能对应多个单词(即在一种语言中,要多个词才能表示另一种语言的一个词)
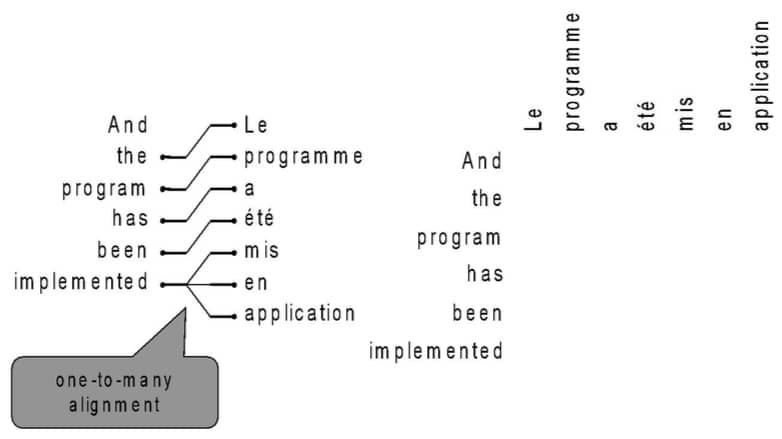
反之亦然
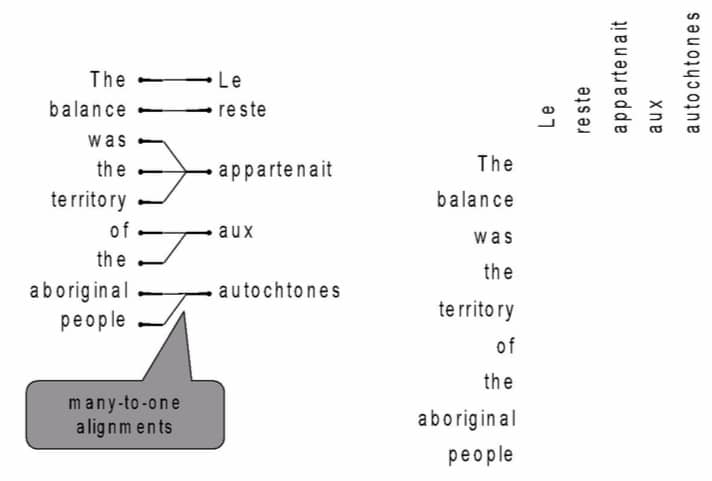
情况三:一种语言的词组,对应另一种语言的词组
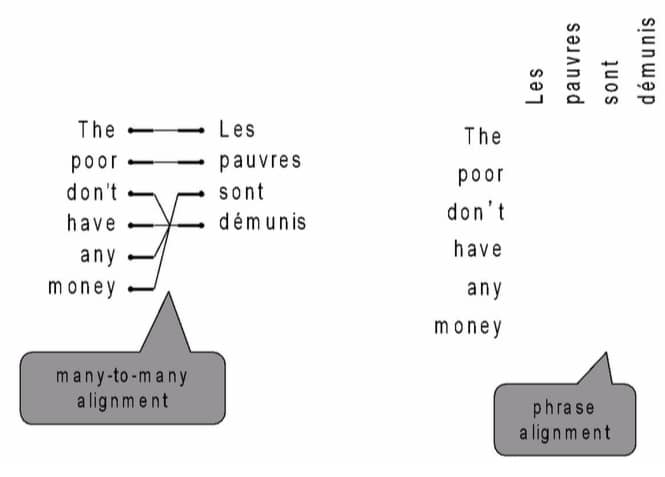
然后根据对应的概率,来寻找最佳的翻译
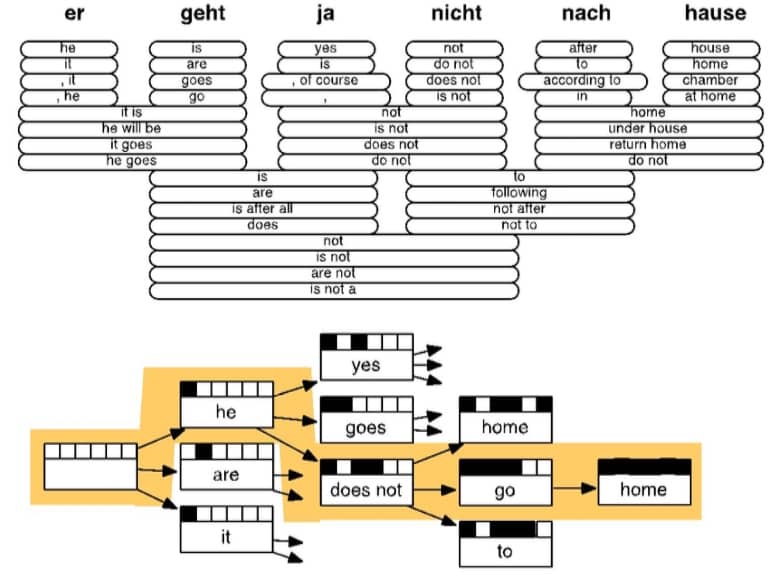
从上面的简单介绍就可以看出,统计机器翻译(SMT)的搜索空间巨大,并且为了要达到比较好的效果,系统会非常复杂,因为:
- 还有成百上千的细节前面没有提及
- 系统包含许多分开设计的子模块
- 特征工程的量非常大
- 需要编译和维护很多附加的资源(比如 equivalent phrases 表)
- 需要非常多的人力来进行维护
2014 神经机器翻译 NMT
神经机器翻译(Neural Machine Translation, NMT)指用一个神经网络来完成机器翻译,这样的网络结果称为 sequence-to-sequence(seq2seq),包含俩 RNN,结构如下:
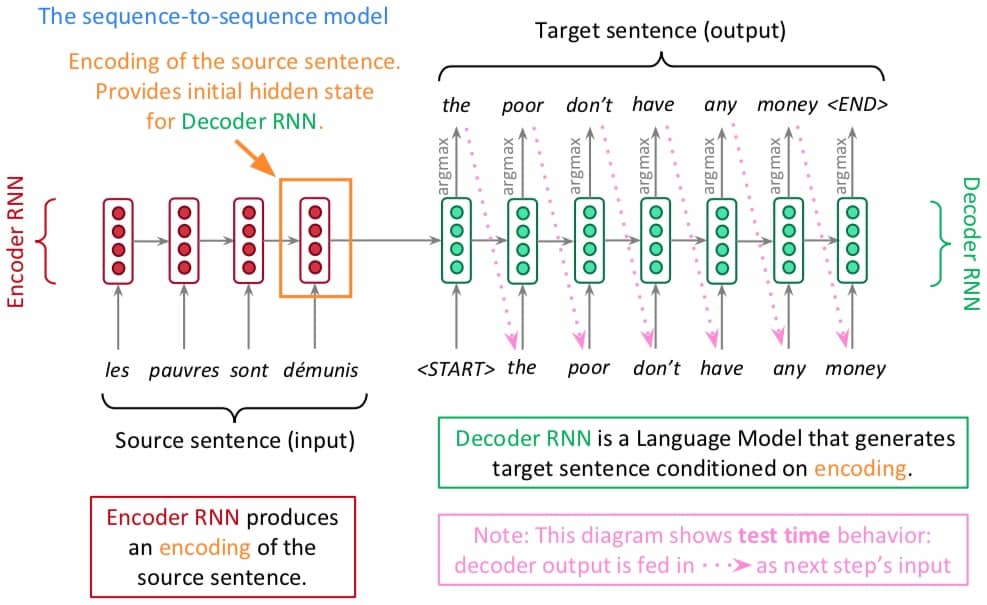
Seq2seq 模型实际上是一个 Conditional Language Model。之所以称为 Language Model,因为 decoder 实际在做的事情就是预测 target sentence y 中的下一个单词。之所以称为 Conditional 因为给出的预测是基于 source sentence x。
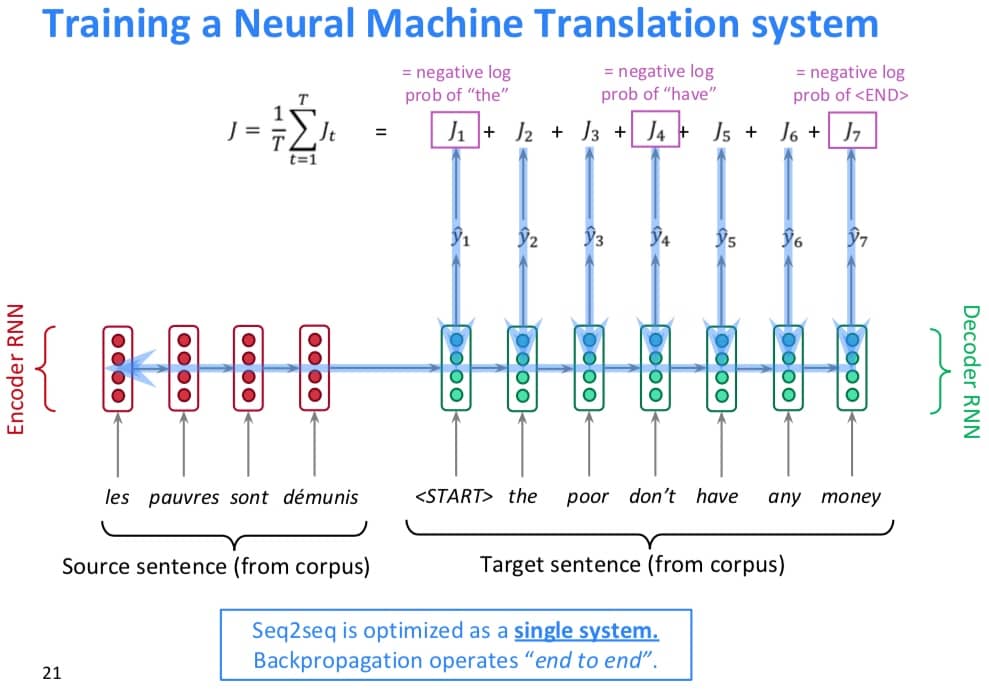
与 SMT 通过贝叶斯定理进行间接计算不同,NMT 直接计算 $P(y|x)$,公式为:
那么问题来了,如何去训练一个 NMT 系统呢?答案是:用很多很多的 parallel corpus。具体的训练如下图所示:
那么我们如何去生成 target sentence 呢?一种方法是总是选择概率最大的那个词(也就是所谓的 argmax),也称为贪心解码(greedy decoding),具体如下:
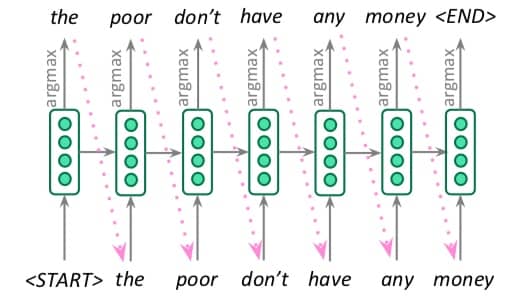
这样做会不会有问题?会!会产生什么问题?这样做出来的选择,是没有办法撤销的,也就是一步错步步错!那么有没有更好的方法?有,就是 beam search!Beam search 会探索若干种可能的组合,并最终选择其中最佳的那个。
理想状态下我们希望找到一个 y 能够让下面公式的取值最大:
最简单粗暴的做法是遍历所有可能的 y,找到最大值,这个计算复杂是 $O(V^T )$,其中 V 是词表大小,T 是 target sequence 的长度。
而 Beam search 的做法就聪明一些,解码器在每一步都会记录 k 个最有可能的 partial translations。这里的 k 就是 beam size,实践中一般在 5-10 之间。虽然这种方法并不能够保证找到最优解,但是效率非常高!下图就是一个搜索的例子:
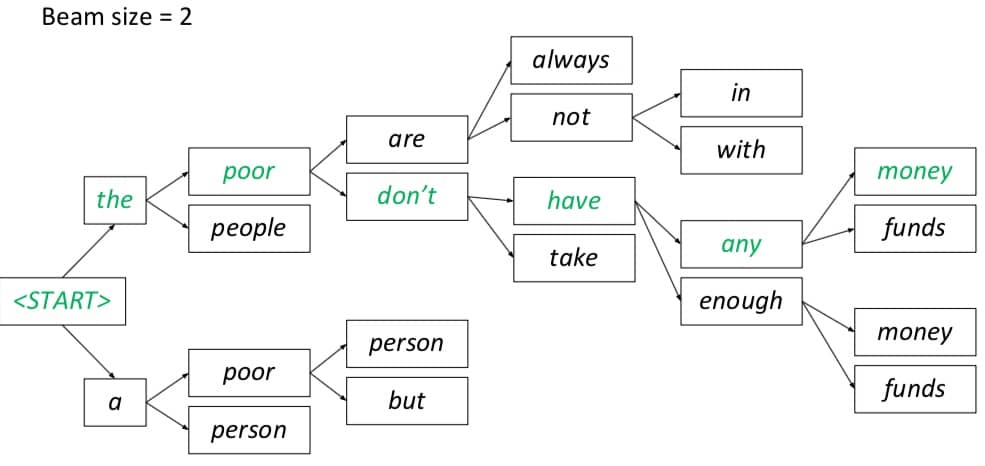
总结一下,NMT 的优势有
- 更好的表现:更流程,更好利用上下文信息,更好利用短语的相似性
- 是一个单一的神经网络,可以端到端进行优化,没有任何子组件
- 不需要太多的人力,不再需要特征工程,不用针对语言进行特殊处理
当然,也有一些劣势
- 解释性较差,比较难调试
- 难以控制,很难按照特定的规则去执行,容易引发问题(比如敏感话题!)
因此,SMT 依然也有其应用场景。
机器翻译的评价标准
我们一般采用 BLEU(Bilingual Evaluation Understudy) 作为机器翻译的评价标准,会用机器的翻译结果与人工翻译的结果计算相似度(一般用 n-gram precision)。但是因为语言本身的复杂性,BLEU 可用但是不完美,比如说好的翻译因为说法不同,很可能得到比较差的 BLEU 结果。
机器翻译已经解决?
值得一提的是,NMT 自 2014 年被提出后,在短短两年的时间里就超越了原来的 SMT,但是离彻底解决还有比较大的距离,还有很多难点,比如:
- 如何处理词表外的词汇
- 如果训练数据和测试数据的领域不同,结果会出现较大偏差
- 对于长文本,如何更好地维护上下文信息
- 如果没有那么多语言对用做训练,如何提高效果
- 对于一些常识内容无法很好进行翻译
- 会学习训练数据中的偏差
- 因为系统不可解释,所以容易出现奇怪的结果
NMT 是深度学习自然语言处理的旗舰任务,基本上引领着 NLP 领域的技术创新。现在对 NMT 的研究仍在继续,研究人员已经对我们今天介绍的普通 seq2seq NMT 系统做了非常非常多的改进。
但是!有一项改进非常重要,现在已经成为了新的标配!这项改进是什么呢?名为 ATTENTION!我们先来看看前面介绍的 seq2seq 的瓶颈在哪里。
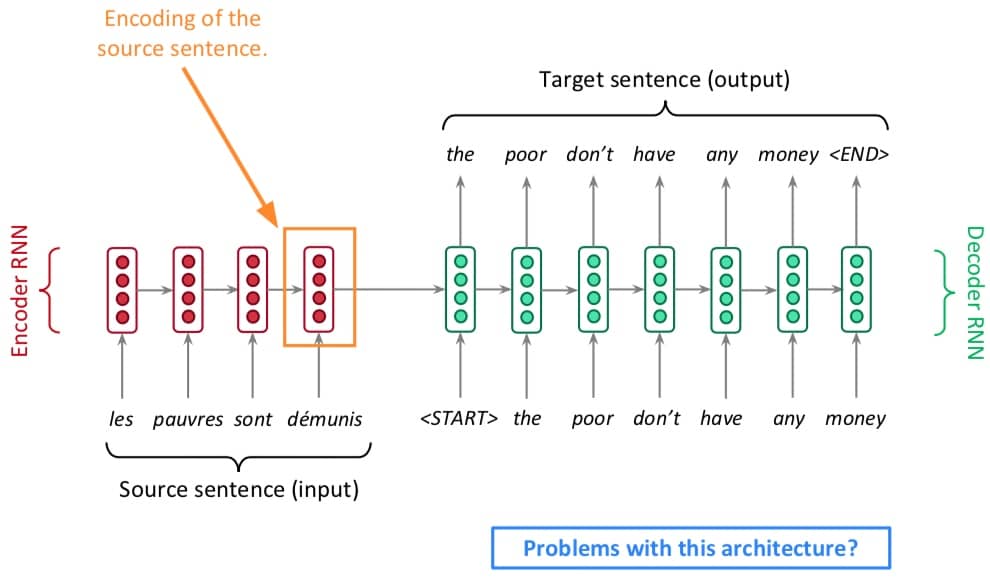
Attention
我们需要在 Encoder RNN 的部分获取所有关于 source sentence 的信息,但是因为输入序列长度是固定的,这里会导致信息瓶颈。而 Attention 机制则针对该瓶颈问题提出了一个解决方法,核心思想是:decoder 的每一步,会分别关注 source sequence 的特定部分。接下来我们一步步来看看所谓 attention 到底是怎么个意思。
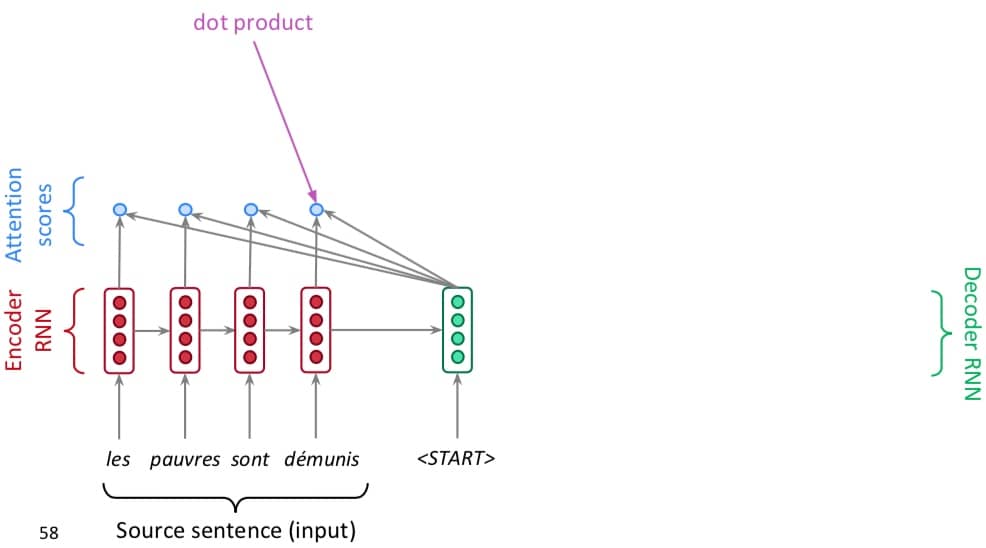
第一步,我们在 decoder 部分对 encoder 每一层的输出做一个点乘。
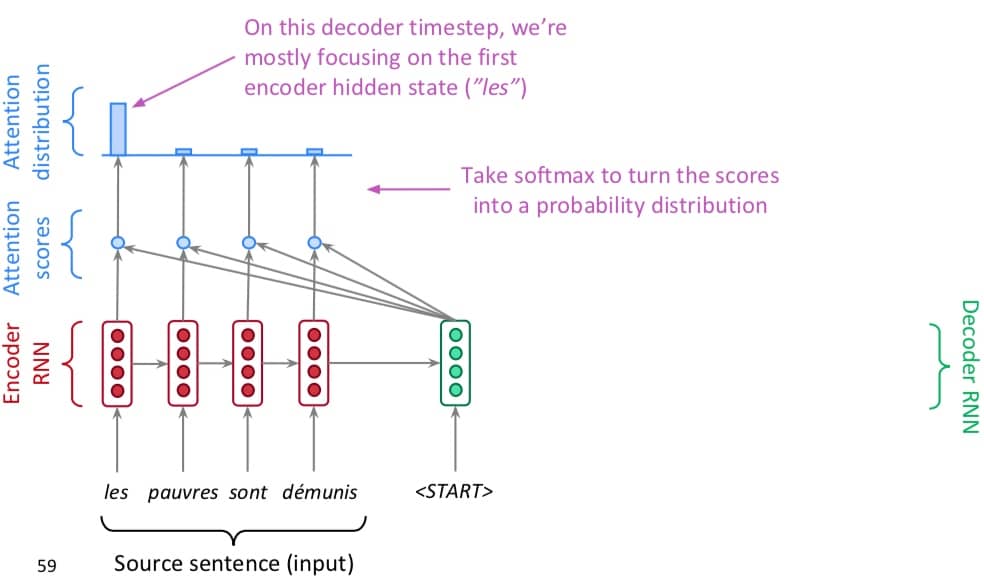
第二步,拿到所有的点乘结果之后,使用 softmax 把它们转化成概率分布,
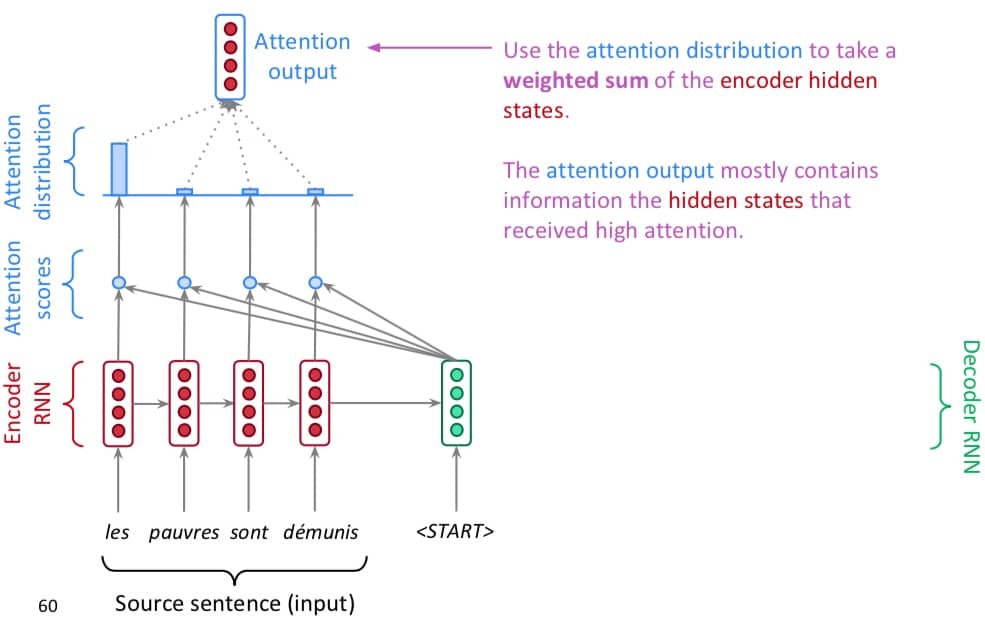
第三步,使用概率分布作为权重,得到每一层的输出加权和,作为 Attention 的输出
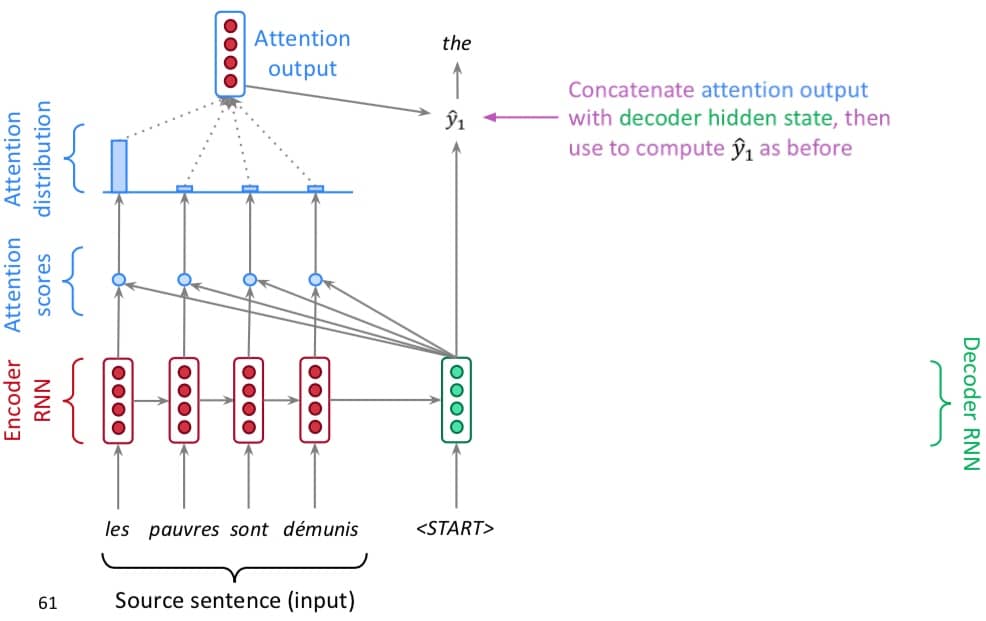
第四步,用 attention output 和 decoder 的输出连接到一起,计算对应结果(这里的计算和之前一样)
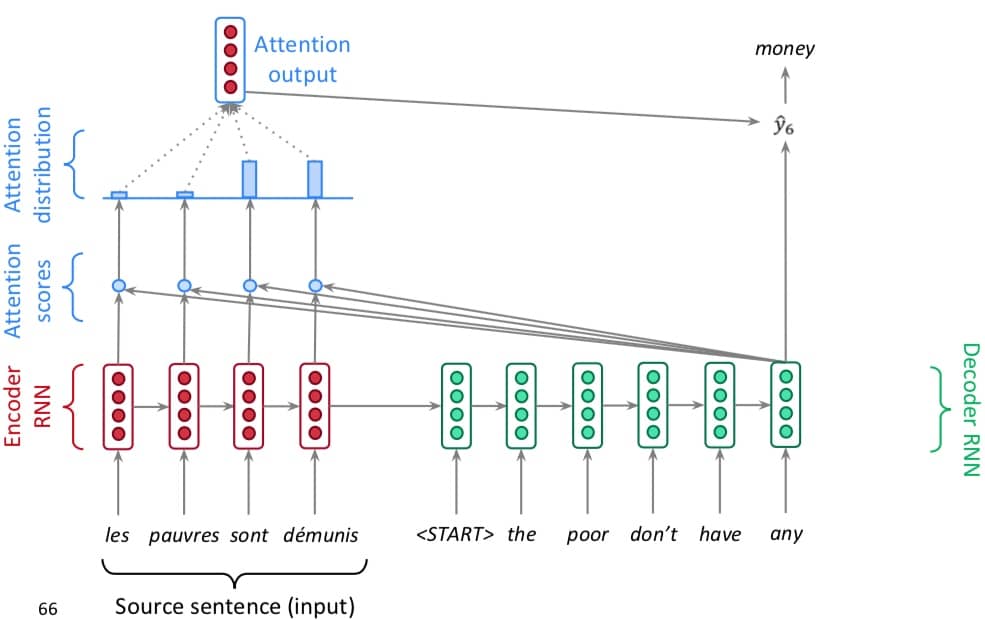
第五步,不断重复前面四个步骤,得到全部的结果,注意图中的 attention 分布已经改变,表示不同层关注的点不一样。
接着我们用公式再描述一遍整个过程:
- encoder 的 hidden state 记为 $h_1,…,h_N \in \mathbb{R}^h$
- 在 timestep t,我们的 decoder hidden state 记为 $s_t \in \mathbb{R}^h$
- 对于该时刻 t 的 attention score $e^t=[s_t^Th_1,…,s_t^Th_N] \in \mathbb{R}^N$
- 给 attention score 计算 attention 分布 $\alpha^t=softmax(e^t) \in \mathbb{R}^N$
- 使用 attention 分布得到 attention output $at=\sum{i=1}^{N} \alpha_i^t h_i \in \mathbb{R}^h$
- 最后把 attention output 和 decoder hidden state 拼起来 $[a_t;s_t] \in \mathbb{R}^{2h}$
Attention 的优点很多:
- 显著提高 NMT 的表现
- 解决了信息瓶颈问题
- 对梯度消失问题有帮助
- 提供了一些可解释性,我们可以通过观察 attention 分布来了解 decoder 具体在关注什么
- 自动进行了 alignment
最后再提一下,seq2seq 的应用非常广泛,除了机器翻译之外,在自动摘要、对话系统、代码生成等领域都有应用。
下期预告
- Transformer