前面我们已经学会了如何构建比较简单的模型,如果要构建和训练更加复杂的模型,我们需要做更多地工作。这节课就以 Word2Vec 模型为例子,来看看构建复杂模型所需要用到东西。
更新历史
- 2019.08.08: 完成初稿
Word2Vec
最简单的表达词汇的方式是 one-hot 编码,但有两个严重的问题:1)词表会非常大,2)无法表示词汇间的关系
简单来说,Word2Vec 做的事情,就是用一种高效地方式去表达文本数据(称为 Word Embedding,Word2Vec 只是其中的一种方式),借此我们可以用来构建语言模型,进行机器翻译、情感分析等任务。
Word Embedding 有啥好处呢?主要有以下四点:
- 分布式表示
- 连续的值(是一个向量)
- 低维
- 可以表示词语间的语义关系
Word2Vec 有两种不同的模型,一个是 skip-gram,另一个是 CBOW。我们先来说说这俩的区别。我们假设一句话是这样的:今天天气真好,那么对于 CBOW 来说,会根据 今天天 和 真好 来预测中间的字是 气。而对于 skip-gram 来说,则是根据 气来预测前面是 今天天,后面是 真好。一般来说 CBOW 对于小数据集比较好,因为会把上下文作为观测,可以学到比较强的规律,而 skip-gram 对大数据集比较好,因为每一个 context-target 组合就是一个新的观测。两种不同模式的模型结构如下:
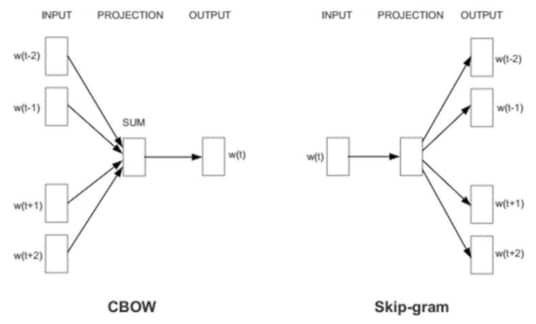
这里我们选择构造 skip-gram 模型,我们会训练一个只有一层隐层的神经网络,但我们不是要神经网络的结果,而是要中间这层隐层的输出,称之为 word vector 词向量。关于 skip-gram 的详细说明感兴趣的同学可以参考 这里
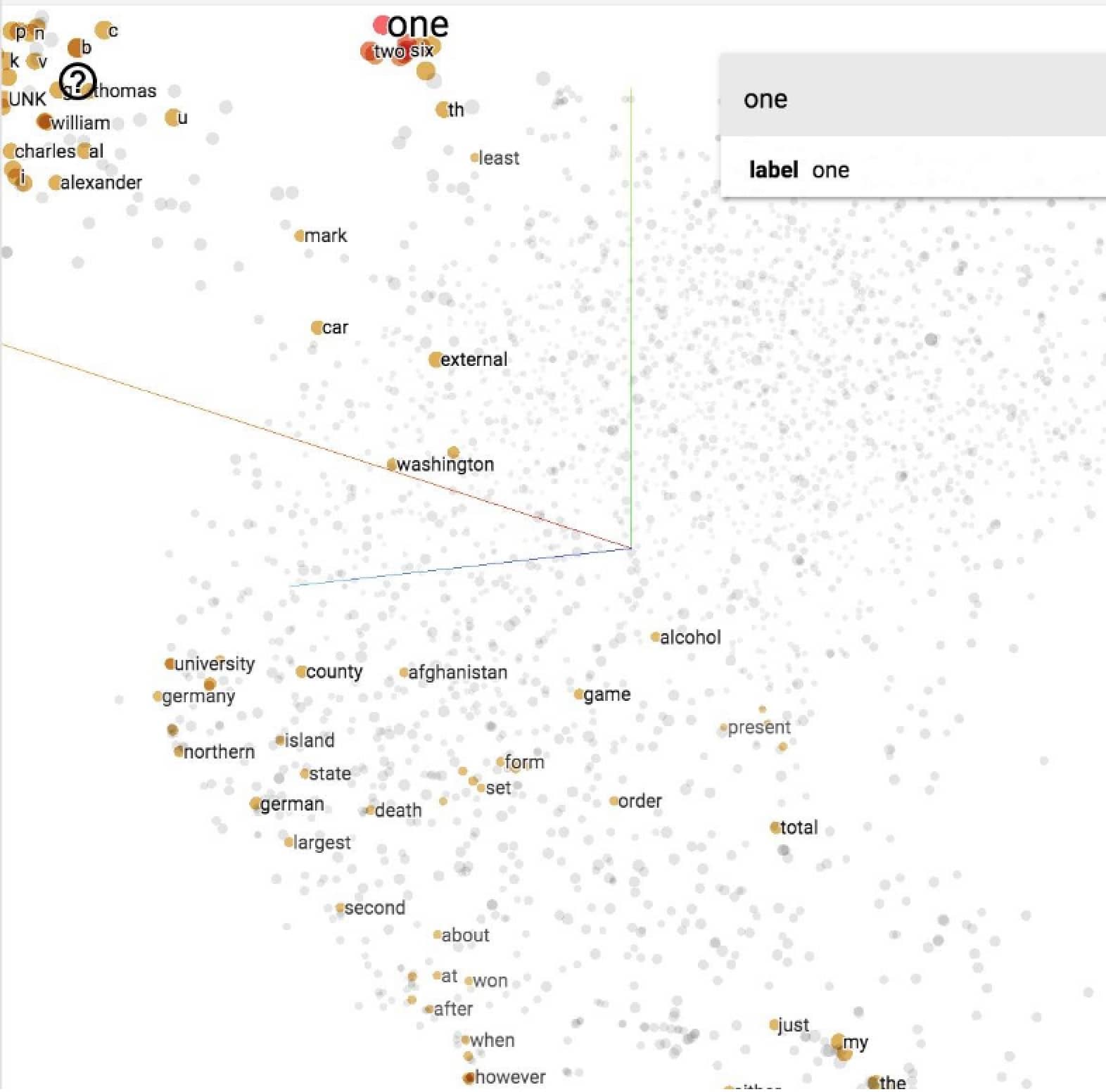
如果把每个词对应的向量显示出来,就会向下图这样(这也可以解释为啥叫词嵌入,就是把词语嵌入到同一个空间中)
Softmax vs Sample-based
因为我们要预测的是相邻词的分布情况,理论上来说,要用 softmax 来计算,把任意一个 $x_i$ 映射到一个概率分布 $p_i$,这样的话 $softmax(x_i)$ 就表示 $x_i$ 与某个词相邻的概率,也就是
注意这里的求和符号,这意味着我们要对每个词都做一次 exp 计算,而词的总数可能高达几百万!即使不考虑生僻词,一个好的语言模型也需要数以万计的常见词构成,这样一来这个计算代价就太大了。为了解决这个问题,人们提出了两种方法(具体参考该论文),分别是 hierarchical softmax 和 sample-based softmax。这里我们直接选择 sample-based 方法,可以训练得更快,得到更好的向量表达。
sample-based softmax 属于 Sample-based 方法,而 Negative sampling 是 Noice Contrastive Estimation(NCE) 的简化版本。更多具体的介绍可以参考 这里 和 这里。
虽然 Negative sampliung 在学习词嵌入时可以起到很大作用,但是从理论上并不保证它与 softmax 函数的梯度近似。但是 NCE 则在 noise sample 增加的时候可以保证这种近似(只要 25 个 noise sample 就可以达到与常规 softmax 接近的结果,但是计算可以加速 45 倍)。因此,我们这里使用 NCE 来进行计算。
注意,这里用 NCE 只是在训练阶段,在实际的预测阶段,还是需要用完整的 softmax 来计算的。
数据集
我们这次使用的数据集叫做 text8,包含 2006 年 3 月 3 日英文维基里前 100MB 清理后的文本,可以在 这里 下载,w2v_utils.py 中的代码可以下载并读取该数据集。
100MB 的数据虽然没有办法训练一个很好的词嵌入模型,但是足够我们来进行学习和探索了,这里包含 17005207 个词(用空格区分)。如果想要得到更好的模型,可以考虑使用 fil9 数据集
具体实现
这里我们会用 eager 模式 和 graph 模式分别进行实现,具体代码请参考 9_w2v_eager.py 和 10_w2v_graph.py,这里只列出一些需要注意的点:
- 每一个输入都是一个标量(这个词对应的词典编号),所以一个 batch 的大小就是
[BATCH_SIZE],对应的输出就是[BATCH_SIZE, 1] - 我们这里设定词向量的大小为
EMBED_SIZE,相当于是隐层有这么多的神经元,而输入层的神经元个数与VOCAB_SIZE相同,所以用来表示他们之间关系的矩阵大小为[VOCAB_SIZE, EMBED_SIZE] - 针对 one-hot 编码的矩阵计算,使用
tf.nn.embedding_lookup方法可以极大降低计算量,直接通过查找获取到 input 对应的 embedding
构建 TF 模型
前面我们构建了几个模型,会发现具体的步骤非常相似:
- 组装 Graph
- 导入数据(通过
tf.data或placeholder) - 定义 weights
- 定义 inference model
- 定义 loss function
- 定义 optimizer
- 导入数据(通过
- 进行计算
- 初始化所有 model variables
- 用训练数据初始化 iterator / feed
- 根据当前的模型参数计算模型输出
- 计算 loss
- optimizer 根据最小化 loss 的方向,更新模型参数
我们把这个过程画出来,像这样:

如果我们想要复用之前写过的代码,最好的方法就是利用 Python 面向对象的能力 —— 写一个类!正好接下来我们要把刚才训练出来的 word2vec 的结果做一个可视化,就一起处理了。
Embedding 可视化
具体的代码请参考 11_w2v_visual.py,这里我们把之前训练的代码封装成了一个类,并且增加了可视化函数,在这个函数中,我们用训练好的网络计算得到前 10000 个单词的隐层向量。计算完成后我们可以用 tensorboard --logdir='data/visualization' 打开 tensorboard 一探究竟。
可视化的方法有几种,这里我们选择 T-SNE,经过一段时间计算后,可以得到类似这样的图:

我们看到这里跟 china 比较相关的词是 australia 和 england,至少都是国家,还可以。其他的结果大家可以自行探索。理论上来说我们可以可视化任何的向量,而不仅仅是 Embedding,详情可以参考 这里
Variable Sharing
我们先来看看刚刚训练 Word2Vec 得到的模型的结构(文件夹 word2vec_simple):
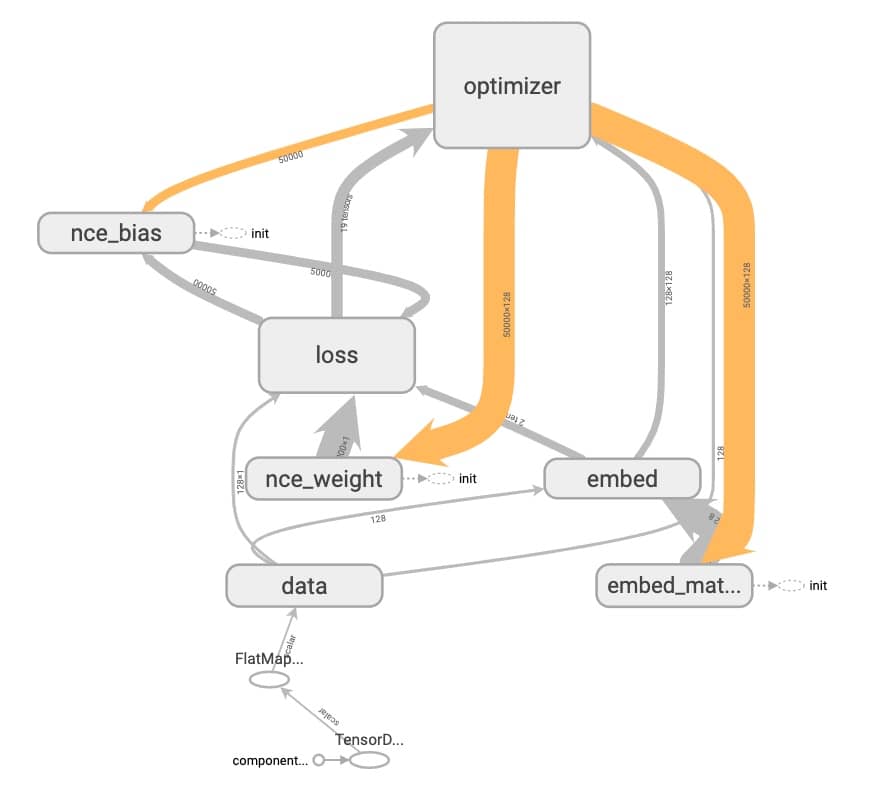
因为我们用不同的 name_scope 标出了不同的操作,模型图看起来就清晰了很多。仔细观察我们可以看到三种不同的箭头:
- 橙色:Reference,比如这里 optimizer 节点就会修改
nce_weight,nce_bias和embed_matrix - 灰色:数据流
- 点点:表示执行依赖,比如
nce_weight这节点一定要在init完成后,才可以执行
那么问题来了 name_scope 和 variable_scope 有啥区别呢?最大的区别在于 variable_scope 可以用来做变量共享。我们用一个实际例子来介绍下这个特性。
我们创建一个包含两层隐层的网络,然后我们给这个网络 x1 和 x2 两个不同的输入,具体代码参考 12_variable_no_sharing.py,注意我们这里使用的是 tf.Variable。运行一下,打开 tensorboard 就会看到(tensorboard --logdir='data/graphs/no_sharing/'),得到的网络是:
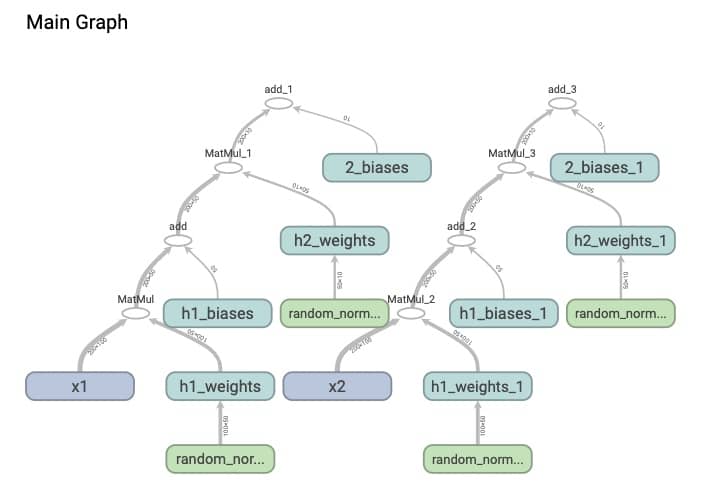
这,我们每输入一个数据集就构建一个新的网络,不科学也不应该。怎么破?我们先把 tf.Variable 改成 tf.get_variable(这个函数会先判断有没有这个变量,如果有会复用),然后再引入 variable_scope,具体代码参考 13_variable_sharing.py。执行之后我们再看一下 tensorboard(tensorboard --logdir='data/graphs/variable_sharing/')
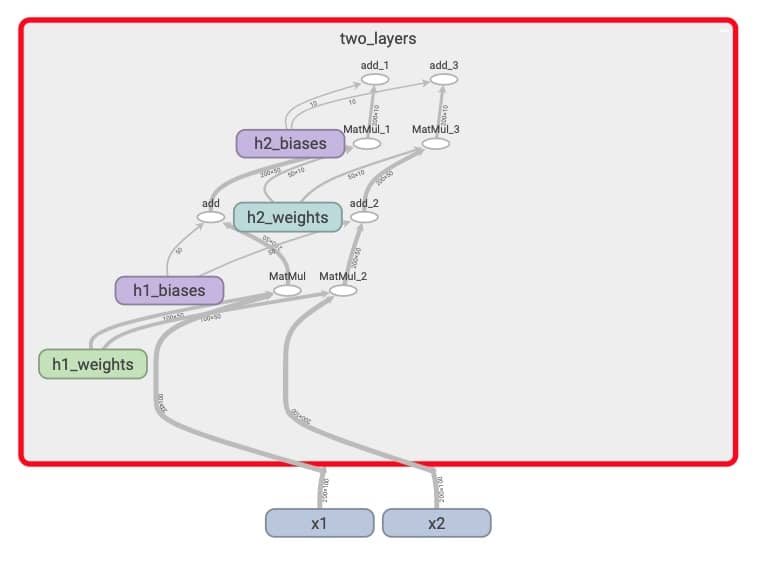
这次我们可以看到,用的是同一套 weight 和 bias 了。再更近一步,我们如果要构建多层结构相似的网络,也可以用更加简洁的代码完成,比如同样是构建两层的全连接网络,我们把每一层的构建抽象出来,就可以轻松复用,具体代码参考 14_fully_connected.py,这里不再赘述(可视化命令 tensorboard --logdir='data/graphs/fully_connected/')。
我们创建模型的时候会用到各类变量,这些变量分散在图的各个位置,我们可以使用 tf.get_collection(key, scope=None) 函数来访问之前定义的变量。所有的变量默认会保存到 tf.GraphKeys.GLOBAL_VARIABLES 中。
管理实验
我们前面训练 Word2Vec 模型大概需要几分钟,但是随着我们的数据集越来越大,模型越来越复杂,计算所需要的时间也会越来越长。我们总不能开始训练之后就等待几天几夜,得到最终结果才据此进行调整。有没有可能随时暂停,检查之后可以继续训练呢?有没有可能随时观察我们模型训练的表现呢?
另外一个要点是构造模型时经常需要用到随机这个功能,我们会随机产生 weights 的初始值,也会随机打乱用来学习的样本。幸运的是,Tensorflow 提供了一系列工具帮助我们完成这些任务。
Saver
训练模型一个很好的实践经验是在训练固定轮次之后,保存模型的参数,这样即使程序崩溃,我们也可以在最后一次保存的基础上继续训练。我们可以使用 tf.train.Saver() 把图中的变量保存到二进制文件中。比如我们想 1000 个 step 保存一次,可以这样写:
1 | # 定义模型 |
完整的代码请参考 11_w2v_visual.py
另外,我们也可以单独保存变量,简单的代码如下:
1 | # pass the variables as a dict: |
Summary
前面介绍的 Saver 只保存变量的值,这里介绍的 tf.summary 则支持记录诸如 loss,accuracy 等信息并动态显示出来。一般来说我们主要用以下三种:
tf.summary.scalartf.summary.histogramtf.summary.image
完整的代码请参考 11_w2v_visual.py,这里挑选核心的代码进行说明
1 | # 首先需要声明需要记录的值 |
具体的操作打开 tensorboard 就一目了然,这里不再赘述
Randomization
如果我们想要得到可以复现的结果,我们就需要控制随机本身,至少我们需要控制决定随机数的 seed,在 TF 中,我们可以这样做:
1 | # 这个对于每个 session 来说是独立的,但是在同一个 session 中 |
如果想要针对整个 graph 进行设定,使用 tf.set_random_seed(seed)
具体的代码可以参考 15_randomization.py
Autodiff
我们知道训练神经网络的梯度是通过反向传播计算的,但是在之前的过程中,我们只关注前向计算,后向似乎都没有任何代码提及,其实是 Tensorflow 帮我们完成了这个步骤。在这个过程中,tensorflow 使用的是 reverse mode automatic differentiation 技术。其中,梯度的计算是通过创建额外的节点和边来实现的,我们看一个实际例子:
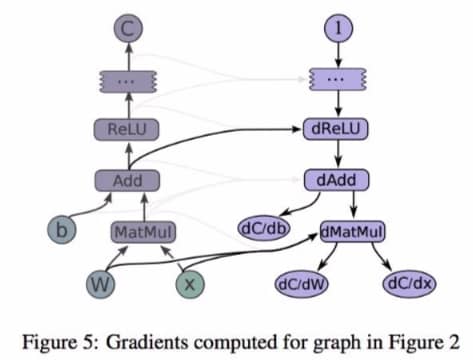
假设我们要计算 C 相对 I 的梯度,TF 首先会寻找这两个节点间的路径,找到之后,TF 从 C 开始并回退到 I,在每一步反向的路径会创建一个节点,根据链式法则计算梯度。假设我们要计算 ys 对于 [xs] 的梯度,可以这么操作
1 | # 这里 xs 是一个 tensor 的列表,计算梯度同样会返回一个梯度的列表 |
既然 TF 帮我们算好了梯度,我们还需要去学习吗?其实还是需要的,毕竟我们还是需要了解其中的原理,来更好地判断模型训练的状态,以及为什么有的模型效果好,有的模型效果差。
下期预告
- 计算机视觉
- 卷积
- CNN